Mechanical Turk 进入维护模式
亚马逊将于 7 月 30 日停止接受新客户,保留现有服务但不再推出新功能,标志着经典众包平台进一步收缩为存量维护。
AI 日报
今天的头条不是单一模型突破,而是 AI 生态在收缩、修正和重组:老平台进入维护模式,前沿模型在工具调用上暴露退化,研究界则在长上下文、检索歧义和文档处理上继续拆解真实瓶颈。与此同时,企业数据控制和生成式视频版权冲突也在把 AI 的使用边界推向更明确的博弈。
Overview
从 12 条资讯中筛选出 9 条
今天的头条不是单一模型突破,而是 AI 生态在收缩、修正和重组:老平台进入维护模式,前沿模型在工具调用上暴露退化,研究界则在长上下文、检索歧义和文档处理上继续拆解真实瓶颈。与此同时,企业数据控制和生成式视频版权冲突也在把 AI 的使用边界推向更明确的博弈。
亚马逊将于 7 月 30 日停止接受新客户,保留现有服务但不再推出新功能,标志着经典众包平台进一步收缩为存量维护。
Claude Opus 4.8 和 Sonnet 5 在嵌套编辑工具调用中出现虚构字段,说明严格 schema 下的工程可靠性仍可能倒退。
百度的 Unlimited OCR 用 R-SWA 把多页识别的 KV cache 增长压住,目标是把长文档处理从逐页循环变成单次推理。
DiscoBench 显示,搜索代理常常不是搜不到,而是不知道何时该停下来问问题,这比单纯检索更接近真实失败模式。
Claude Code 和 Fable 5 在数小时内完成 iOS 移植与稳定版审查,分别展示了跨平台移植和发布前缺陷发现的实际价值。
Mistral CEO 与好莱坞对 Seedance 的反应都在强调同一件事:谁控制模型、数据和使用边界,正在成为 AI 落地的核心问题。
AI 正从“能力竞赛”转向“可用性、控制权与工作流适配”的阶段。今天的故事共同指向一个判断:真正决定 AI 落地效果的,不只是模型更强,而是它是否能稳定接入现有系统、理解歧义、尊重 schema,并在商业和法律边界内运行。
今天的信号很清晰:AI 产业的下一阶段不只看模型参数和榜单,更看它能否被可靠地嵌入真实业务、真实数据和真实合规环境。基础设施在收缩,工具在校准,争议在升级,落地门槛也在同步抬高。
Stories
TechCrunch AI

亚马逊表示,Mechanical Turk 将于 2026 年 7 月 30 日起停止接受新客户。现有客户仍可继续正常使用该服务,但 AWS 说不会再推出新功能,只会继续进行安全性和可用性改进。
这标志着这家最知名的众包平台之一出现了明显收缩,也说明 Mechanical Turk 正在进一步进入维护模式。对于长期依赖该平台进行 AI 训练、数据标注和人机协作流程的企业来说,这一变化具有直接影响。
亚马逊宣布,从 2026 年 7 月 30 日开始,Mechanical Turk 将停止接收新客户,这一消息发布在该服务的网站上。AWS 表示,这一决定经过了“仔细考虑”,并强调现有客户仍然可以像往常一样继续使用该平台。公司还说,后续会继续进行安全性和可用性方面的改进,但不会再推出新功能。换句话说,这并不是彻底关闭服务,而是让它进入一种几乎只维持运转的维护模式。Mechanical Turk 最早于 2005 年推出,定位是一个众包市场,用户可以拿到很少的报酬来完成一些难以完全自动化的小任务。
它后来一度成为众包劳动伦理争议的中心,并在 2018 年被亚马逊重新包装为 SageMaker AI 里的数据标注工具,用来训练神经网络。与此同时,该平台也常被视为“假装是 AI、实际上依赖人工”的幕后支撑,这也呼应了原始 Mechanical Turk 这个魔术骗局:看起来像机器在下棋,实际上里面藏着一名人类棋手。更复杂的是,一项 2023 年的分析发现,平台上有 33% 到 46% 的工人会用大语言模型来完成任务,这让数据标注的可靠性以及“是否仍然需要人类介入”都受到质疑。消息公开后,一些 Reddit 用户认为这个平台“几年前就已经死了”,原因是机器人、欺诈和使用量下降。整体来看,这次公告更像是对 Mechanical Turk 时代结束的一次正式确认,而不是突如其来的关停。
Mechanical Turk 于 2005 年首次推出,最初用于一些难以自动化的小任务,例如解决 CAPTCHA 和做情感标签。亚马逊后来在 2018 年把它重新定位为 SageMaker AI 里的数据标注工具,但该平台也一直因欺诈、机器人和劳动问题而受到批评。
The Decoder

·#ocr
百度研究人员提出了“Unlimited OCR”,这是一种可以在一次推理中处理几十页文档、并且随着输入增长仍保持内存占用和速度基本恒定的 OCR 系统。该模型通过将标准注意力机制替换为一种名为参考滑动窗口注意力(R-SWA)的新机制来实现这一点。
如果这种方法在论文之外也能稳定工作,它可能会让长文档 OCR 和文档理解流程更高效,尤其适用于目前必须逐页循环处理的系统。它也反映了更广泛的长上下文趋势:通过重新设计注意力机制,让模型在处理更长输入时避免内存膨胀。
百度研究人员推出了一种名为 Unlimited OCR 的 OCR 模型,可以在一次推理过程中处理几十页文档。研究团队要解决的核心问题是:现有端到端 OCR 系统通常依赖语言模型解码器,而解码器的 KV cache 会随着生成文本变长而不断增长,从而导致内存占用上升、推理速度变慢。现实中,很多系统只能按页循环处理文档,并在每一页结束后重置 cache。百度用一个类比来解释他们的思路:就像人抄书时不会反复回头重读已经写过的所有内容,而是主要关注原文、刚写下的几个字,以及接下来要写的字,旧内容会像被“软遗忘”一样逐渐淡出。支撑这一设计的技术是 Reference Sliding Window Attention,简称 R-SWA。它让生成的 token 仍然可以关注所有参考输入,但对已经生成的输出只保留最近 128 个 token 的可见范围,因此整个过程中的 KV cache 保持恒定。与此同时,百度还避免让视觉 token 受到同样的滑动窗口状态变化影响,因为那样会逐渐模糊图像特征并降低识别效果。
Unlimited OCR 基于开源的 Deepseek OCR 构建,保留了 DeepEncoder,并搭配一个 30 亿参数的 mixture-of-experts 架构,但推理时只有大约 5 亿参数在 सक्रिय状态。百度表示,训练数据约有两百万个文档样本,其中单页数据和多页数据按 9:1 划分,多页数据还是通过把单页样本拼接成 2 到 50 页的文档来合成的。训练时所有数据被打包成 32,000 token 的序列,在 8 组 16 张 Nvidia A800 GPU 上进行了 4,000 步训练,且 DeepEncoder 保持冻结,只更新语言模型参数。根据作者的说法,在 OmniDocBench v1.5 上,该模型的综合得分达到 93%,比 Deepseek OCR 基线高出 6 个百分点,其中表格结构识别提升尤其明显。到了更新的 v1.6 版本,它的得分达到 93.92%,位居端到端系统排名前列。在长程测试中,模型即使处理超过 40 页,错误率仍低于 0.11,而剩余错误被作者归因于 Base 模式下 DeepEncoder 的分辨率上限,而不是上下文丢失。
R-SWA 允许每个输出 token 关注全部参考 token,例如图像 token 和提示词,但只回看最近 128 个已生成 token,从而让 KV cache 保持固定而不是线性增长。百度表示,他们把解码器中的标准注意力层全部替换为 R-SWA,而 DeepEncoder 保持冻结,只训练语言模型参数。
Simon Willison
Simon Willison 转述了 Armin 在 Pi 中发现的一个回归问题:较新的 Anthropic Claude 模型,包括 Opus 4.8 和 Sonnet 5,有时会在嵌套的 edits[] 数组里生成带有虚构字段的错误编辑工具调用。虽然编辑内容通常是对的,但参数不符合 schema,导致 Pi 拒绝该调用并要求重试。
这对依赖严格工具 schema 的 AI agent 和编程工具来说是一个实际的可靠性问题。它说明更先进的前沿模型在某个狭窄但关键的任务上,可能会比旧模型表现更差,这会迫使开发者加入针对不同模型的兼容方案,甚至实现多套编辑工具。
2026 年 7 月 4 日,Simon Willison 发表了一篇名为《Better Models: Worse Tools》的链接文章,介绍了 Armin 在开发 Pi 时遇到的一个 bug。问题在于,较新的 Claude 模型有时会生成编辑工具调用,并在嵌套的 edits[] 数组中加入额外的、臆造出来的字段。虽然模型给出的编辑内容通常是正确的,但工具参数不符合 Pi 的 schema,因此系统会拒绝这次调用并要求模型重试。Willison 说,工具调用格式错误本身并不罕见,尤其是在较小模型上。
真正令人意外的是,这种情况似乎在更新的 Anthropic 模型中更严重,例如 Opus 4.8 和 Sonnet 5,而旧模型并没有这个问题。Armin 认为,这可能与 Anthropic 近期的训练有关,尤其是为了让模型更擅长 Claude Code 内置编辑工具而进行的优化。这样的训练可能提升了 Claude 自家工具的表现,却让第三方工具框架,比如 Pi,更容易遇到错误的工具调用。Willison 最后提出一个问题:Pi 这类工具是否应该支持多种编辑工具格式,以便根据用户选择的模型切换到表现最佳的那一种。
Armin 怀疑这个回归可能来自 Anthropic 最近的训练方式,可能是为了提升 Claude Code 内置编辑工具而做的强化学习。Simon 还指出,Claude 的编辑工具采用的是搜索并替换语义,而 OpenAI 的 Codex 使用的是 apply_patch 机制,这说明不同模型家族的工具行为可能差异很大。
The Decoder

Google DeepMind 开发者 Ammaar Reshi 使用 Anthropic 的 Claude Code 和 Fable 5,在短短几小时内把 2003 年的即时战略游戏《Command & Conquer: Generals Zero Hour》移植到了原生 iPhone 和 iPad。该游戏现在可在 ARM64 上直接运行,无需模拟器,而且战役、遭遇战和 Generals Challenge 模式都支持触控操作。
这为 AI 辅助游戏移植提供了一个很强的概念验证,说明老旧 PC 游戏可以在很短时间内被迁移到现代移动硬件,并达到可玩程度。它也表明,AI 编程工具正越来越多地用于复杂的跨平台工程工作,而不仅仅是简单代码生成。
Google DeepMind 的开发者 Ammaar Reshi 使用 Anthropic 的 Claude Code 和 Fable 5,把 2003 年的 PC 即时战略游戏《Command & Conquer: Generals Zero Hour》移植到了原生 iOS。Reshi 目前担任 Google AI Studio 的产品与设计负责人。根据他的说法,第一个可用版本大约在 40 分钟内完成,随后又花了几个小时进行调试。这个版本可以在 ARM64 上直接运行,不依赖模拟器。游戏的战役、遭遇战以及 Generals Challenge 模式都能正常工作,并支持触控操作。
图形渲染路径则通过多个中间步骤,把 DirectX 8 转换为苹果的 Metal API。Reshi 还表示,他在两天内就把 Claude Max 额度全部用完了。随后,他把完整源代码以开源形式发布到了 GitHub,但不包含游戏资源;如果想实际运行,用户需要自己拥有该游戏的 Steam 版本,售价大约 5 美元。Reshi 还指出,iPad 在长时间游玩时仍可能因为内存占用过高而崩溃,而且相关工程日志记录了整个移植过程中的 bug 和修复。
Reshi 表示,第一次构建大约用了 40 分钟,之后又花了几个小时调试,并且在两天内耗尽了 Claude Max 额度。渲染路径通过多个中间步骤把 DirectX 8 转换为苹果的 Metal API;相关开源代码已发布到 GitHub,但不包含游戏资源,用户需要自己拥有 Steam 版本,而且 iPad 在长时间运行时仍可能因为内存占用过高而崩溃。
The Decoder

腾讯混元和清华大学的研究人员提出了一个名为 DiscoBench 的新基准,结果显示 AI 搜索代理往往不是卡在检索本身,而是没能尽早识别查询歧义并提出澄清问题。研究还发现,当代理一直沿着错误方向重复搜索时,效果甚至可能比直接猜测更差。
这之所以重要,是因为现实中的检索问题常常是不完整、含糊甚至有误的,如果搜索代理不能识别这些歧义,就会不断偏离正确答案。这个结果说明,代理式搜索系统的核心短板不只是检索能力,还包括判断何时停下来并向用户澄清的对话能力。
这篇文章的核心观点是,AI 搜索代理最常见的失败并不是不会搜,而是不知道什么时候该向用户确认问题。腾讯混元和清华大学的研究人员为此提出了 DiscoBench,用来测试模型能否在多步研究过程中识别歧义、提出有针对性的追问,并把搜索路径拉回正轨。与 GAIA、BrowseComp 等早期基准不同,DiscoBench 并不默认用户问题已经完整清晰,而是专门围绕含糊、不完整或有误的真实查询来设计。该基准包含 211 个任务和 463 个歧义点,覆盖 11 个知识领域,每个任务又被拆成多个检查点,代理需要在“继续搜索”“向用户提问”“直接回答”之间做选择。研究人员把歧义分为四类:一个描述可能对应多个实体、可能涉及不同时间段或版本、可能存在多种有效的排名或评估标准,或者干脆包含事实错误。
为了更贴近真实使用场景,数据集大部分以中文编写,反映中文网络上的常见搜索方式。只要代理提出了有用的澄清问题,模拟用户就会给出一个预设线索,从而帮助缩小搜索范围。结果显示,单步表现和端到端结果之间存在明显落差,例如 Claude Opus 4.7 在单个检查点上能答对 57%,但完整任务成功率只有 39.8%。文章还指出,仅仅在系统提示里要求模型“注意歧义”并不够,而如果模型一开始就走错理解方向,继续搜得越多,往往反而比直接猜测更糟。
DiscoBench 包含 211 个任务、463 个歧义点,覆盖 11 个领域,包括电子游戏、体育、音乐、电影、科学和政治。该基准评估模型能否识别歧义、提出有用的追问并修正搜索路径;即使 Claude Opus 4.7 在单个检查点上也有 57% 的正确率,端到端结果却只有 39.8%。
Simon Willison
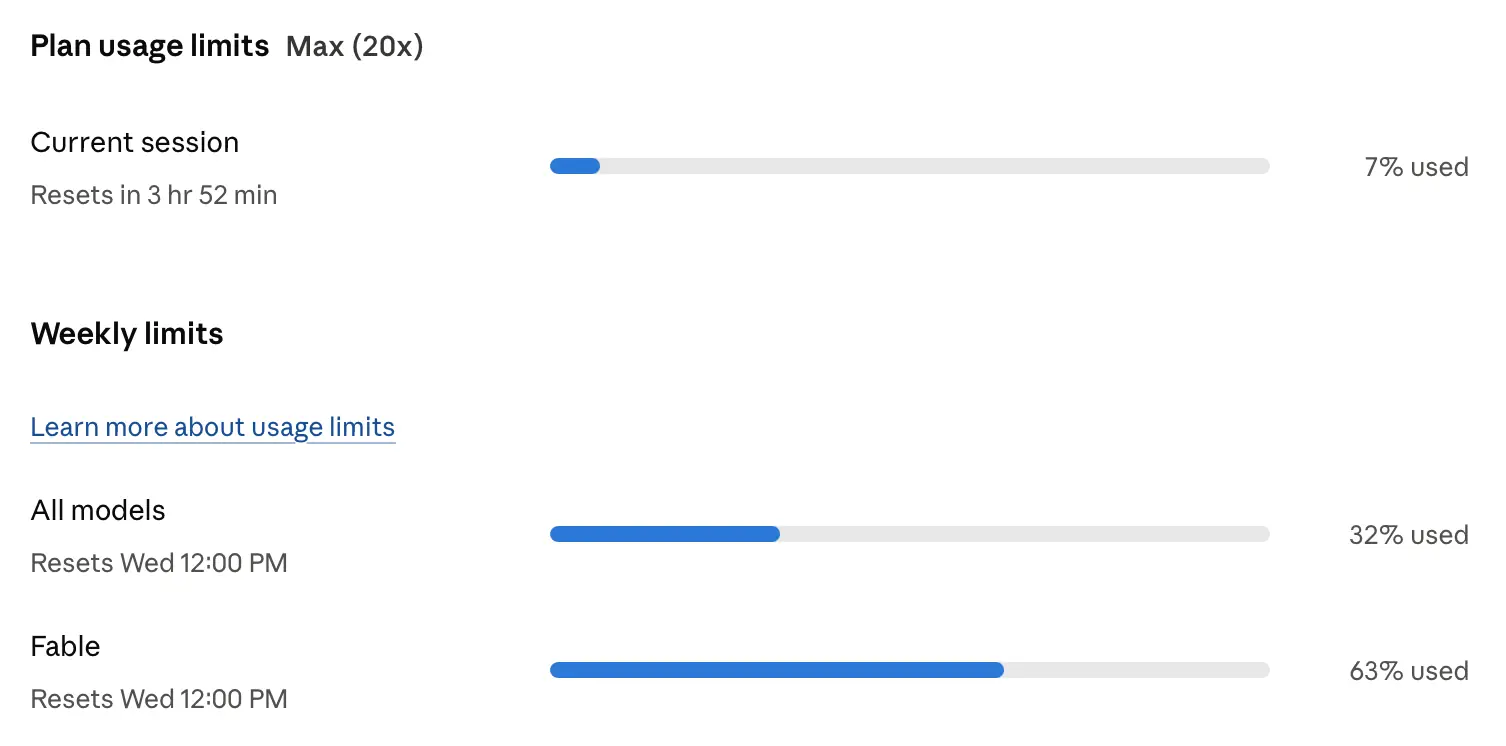
Simon Willison 表示,sqlite-utils 4.0rc2 在 Claude Fable 的大量帮助下完成打磨,后者在稳定版发布前的最终审查中找出了 5 个发布阻塞问题。此次工作共形成 34 次提交、修改 30 个文件,Claude 的使用成本约为 149.25 美元。
这篇文章给出了一个具体案例:AI 辅助代码审查在重大版本发布前发现了严重的数据丢失漏洞,这对需要遵守 SemVer 承诺的开源维护者尤其重要。它也说明编码代理不仅能写代码,还可以用于成熟库的定向稳定性修复。
Simon Willison 说,他在推进 sqlite-utils 4.0 稳定版之前,先让 Claude Fable 对 4.0rc2 做了一次最终审查。此前他已经写过 4.0rc1 的发布说明,但希望在进入稳定版前再确认没有会迫使之后发布破坏性修复的遗留问题。于是他先在 iPhone 上的 Claude Code for web 中输入提示,请求对稳定版发布前的关键内容做最后检查。Claude Fable 给出的初始报告找出了 5 个发布阻塞问题。最严重的问题是 delete_where() 没有正确提交 DELETE 操作,并把连接留在 in_transaction 状态,导致后续的 atomic 操作都走保存点分支而不会真正提交。
Willison 复现了这个问题,发现它会造成数据丢失:删除、后续插入以及其他表的写入在重新打开数据库后都消失了。尽管如此,他认为这仍然可以通过 4.0.1 这样的补丁版本修复,而不必上升到 5.0 级别的设计变更。整个过程持续了 37 次提示、34 次提交,以及跨 30 个文件的 +1,321/-190 代码变更。Willison 还提到,编码代理的一个优点是此类任务常常需要 10 到 15 分钟的自动处理时间,让他可以同时去做别的事情,比如去参加 Half Moon Bay 的 7 月 4 日游行。最后的审查转移到他的笔记本电脑上,并通过 GitHub 的 PR 界面完成;新版还补充了新的事务模型文档,强调所有写入方法都会在返回前完成提交。
最严重的问题是 delete_where() 没有正确提交事务,并让 SQLite 连接停留在事务状态,导致后续 atomic 操作也无法正常提交,从而可能在重新打开数据库后丢失数据。Willison 还表示,新的 4.0 版本明确记录了一个事务模型:所有写入方法都会立即提交,包括通过 db.execute() 执行的写语句。
Simon Willison

Simon Willison 的文章介绍了 Iwo Kadziela(由 Codex 协助)实现的一种浏览器技巧,只用 445 字节的数据就能渲染出一幅相当可信的 ASCII 世界地图。这个方法把 deflate 压缩和一段极短的 JavaScript 组合起来,在页面中解压并显示地图。
这是一个很有代表性的浏览器端极限代码与数据压缩示例,展示了现代 Web API 在超小型自包含演示中的可玩性。它最值得网页开发者和代码极限压缩爱好者关注,因为其中涉及压缩技巧、data URL 以及轻量级前端渲染。
Simon Willison 介绍了一个名为“用 500 字节构建世界地图”的项目,展示了如何用极少的数据生成一幅看起来相当可信的 ASCII 世界地图。这个成果归功于 Iwo Kadziela,并且在 Codex 的协助下完成,最终地图只用了 445 字节的数据。文章强调,关键并不是复杂的渲染引擎,而是一个被高度压缩的有效载荷,加上一小段 JavaScript 连接逻辑。那段 JavaScript 先用 `fetch()` 读取 `data:` URI,再把响应体交给 `DecompressionStream('deflate-raw')` 解压。
解压后的内容随后被转成文本,并作为 `<pre>` 元素插入页面。地图本身由 ASCII 字符组成,作者认为在如此小的体积下效果出乎意料地好。Willison 还提到,他之前并不知道 `fetch()` 可以这样配合 `data:` URI 使用,这也是这个技巧值得注意的原因之一。该帖子是通过 Hacker News 被发现的,但整体上它仍然主要是一个聪明的浏览器黑客技巧和代码压缩演示。
这个实现使用 `fetch()` 读取 `data:` URI,然后把响应流通过 `DecompressionStream('deflate-raw')` 解压,再转成文本并插入到 DOM 中。最终效果是一幅用很小字号显示的 ASCII 地图;文章也把它定位为一个巧妙的技术趣味展示,而不是重大的实用突破。
The Decoder

Mistral 创始人兼首席执行官 Arthur Mensch 在领英发文称,封闭式 AI 模型会让实验室对客户的业务流程拥有“前排视角”。他建议企业把数据保留在开放系统中,自行制定 AI 访问规则,并尽可能自己训练模型,而不是依赖专有供应商。
这番表态凸显了企业越来越担心的问题:使用封闭式 AI 服务虽然方便,却可能把敏感的业务流程数据集中交到模型供应商手中。对于正在评估 AI 落地的公司来说,这场争论尤为重要,尤其是那些把业务流程和专有知识视为竞争优势的行业。
Mistral 创始人 Arthur Mensch 通过一篇领英帖子强调开源 AI 的价值,并提醒企业不要过度依赖封闭式模型供应商。 他声称,销售封闭式 AI 模型的公司会不断积累更多数据,从而能够窥见客户的业务流程。 Mensch 还表示,一些 AI 实验室过去会利用这些信息去争取它们最成功的客户。 因此,他建议企业把数据保留在开放系统中,自己定义 AI 的访问控制,并尽可能自行训练模型,即使这些做法看起来很困难。 他用一句话概括自己的观点:前沿 AI 确实能推动业务增长,但如果不掌握在企业自己手里,这种增长就不真正属于企业。
文章指出,这一立场与 Palantir 首席执行官 Alex Karp 的观点相呼应,后者也主张企业应当自己构建 AI 系统,而不是依赖外部专有工具。 Palantir 还发布过一份关于安全 AI 的宣言,强调控制模型权重的重要性。 不过文章也提醒,Mensch 的发言有明显的商业背景,因为 Mistral 正在借助“欧洲主权 AI”的叙事争取市场,而它在原始性能上并不一定能和顶级专有模型正面竞争。 文中最后提到,一项关于金融文档分析的实验在某种程度上支持了他的说法:当训练数据里没有包含足够的内部领域知识时,企业自有知识可能帮助微调后的开源模型取得更好结果。
Mensch 的观点也带有明显的战略意味,因为文章指出,Mistral 正在把自己定位为欧洲重要的 AI 替代方案,但在原始性能上并不一定能与顶级专有模型匹敌。文中还提到一项金融文档实验:Bridgewater 和 Thinking Machines Lab 声称,经过微调的开源 Qwen3-235B 模型准确率达到 84.7%,而最佳前沿模型为 78.2%,运行成本还低了将近 14 倍。
The Decoder

好莱坞团体正在公开施压,要求阻止字节跳动的 AI 视频工具 Seedance,原因是版权担忧;此前一段包含布拉德·皮特和汤姆·克鲁斯的 15 秒 AI 视频走红后,美国电影协会曾向字节跳动发出停止侵权函。与此同时,《洛杉矶时报》报道称,业内工作室和创作者仍在幕后对这款工具表现出强烈兴趣并继续使用它。
这凸显了版权执法与娱乐行业快速采用 AI 视频工具之间日益加剧的冲突。如果 Seedance 成为一个典型案例,它可能会影响片方、电影人和 AI 公司如何在专业工作流中协商生成式视频的使用方式。
字节跳动的 AI 视频工具 Seedance 正在好莱坞成为一个争议焦点,因为它同时触及了生成式 AI 的热度和版权方面的焦虑。此前一段 15 秒的 AI 生成视频走红,视频中出现了布拉德·皮特和汤姆·克鲁斯在打斗的场景,这让争议进一步升级。随后,美国电影协会向字节跳动发出了停止侵权函,指控其对成员制片厂的版权构成“系统性侵权”。不过,报道显示,这种法律层面的施压并没有阻止字节跳动继续扩大其在美国的存在。
公司今年春天在圣莫尼卡公开演示了 Seedance,还发布了 100 个美国职位,并在戛纳的鱼子酱活动以及亚马逊的 AI 活动上露面。与此同时,字节跳动还被报道已经签下几位独立电影人,并开始讨论资助 AI 生成电影。洛杉矶时报援引的业内人士则表示,许多创作者认为 Seedance 是目前最好的视频生成工具之一,一些工作室虽然没有正式批准它,但实际上在“别问别说”的默许状态下使用。于是,Seedance 在好莱坞呈现出一种分裂局面:公开层面强烈反对,私下却充满好奇和实际采用。
文章称,字节跳动今年春天在圣莫尼卡活动中展示了 Seedance,还发布了 100 个美国岗位、在戛纳办了鱼子酱派对,并在亚马逊的 AI 活动上举办了讨论环节。顾问 Peter Csathy 认为它目前是市场上最好的视频工具,而《辛普森一家》动画制片人 Joel Kuwahara 则表示,一些工作室正以“别问别说”的方式使用它。