LiteParse可在浏览器中运行,实现PDF文本提取
Simon Willison··作者 Simon Willison
关键信息
浏览器版本支持OCR(通过Tesseract.js)和非OCR文本提取,并提供渲染页面截图选项,可直接在浏览器中复制提取的文本或JSON输出。
资讯摘要
西蒙·威尔森展示了LiteParse——一个原本为Node.js设计的快速开源PDF解析器——现在可以完全在浏览器中运行,利用PDF.js和Tesseract.js等现有库。该工具执行空间文本解析,意味着它能保留每页上的文字布局,检测列、段落等结构。用户可上传任意PDF文件,选择是否运行OCR,并获取纯文本或包含每个文本元素位置信息的结构化JSON。
这支持强大的应用场景,比如AI问答系统中的视觉引文,即用原始文档中的高亮图片佐证答案。演示版托管在simonw.github.io/liteparse,无需服务器处理。
资讯正文
LlamaIndex有一个非常出色的开源项目叫做<a href="https://github.com/run-llama/liteparse">LiteParse</a>,它提供了一个基于Node.js的命令行工具,用于从PDF中提取文本。我实现了一个完全在浏览器中运行的LiteParse版本,使用了与Node.js版相同的大部分库。
<h4 id="spatial-text-parsing">空间文本解析</h4>
令人欣慰的是,LiteParse并不依赖AI模型来完成其工作:它采用传统的PDF解析方式,对于包含图片而非原始文本的PDF,则回退到Tesseract OCR(或其他可插拔的OCR引擎)进行处理。
LiteParse解决的核心难题是在PDF布局极其混乱的情况下,仍能以合理顺序提取文本。他们将这种技术称为“空间文本解析”——通过一些非常巧妙的启发式算法检测多栏布局,并将文本按合理的线性顺序分组返回。
LiteParse的文档描述了一种实现<a href="https://developers.llamaindex.ai/liteparse/guides/visual-citations/">视觉引用(带边界框)</a>的模式。我非常喜欢这个想法:能够根据PDF回答问题,并附上裁剪和高亮后的图像,这似乎是一种增强基于RAG问答系统答案可信度的好方法。
LiteParse目前仅作为一个纯命令行工具提供,专为代理程序设计。你可以这样运行它:
<pre><code>npm i -g @llamaindex/liteparse
lit parse document.pdf
</code></pre>
我<a href="https://claude.ai/share/44a5ed86-e5b5-4e14-90be-1eba1e0acd13">用Claude探索了它的功能</a>,很快发现没有理由让它停留在命令行应用:它建立在PDF.js和Tesseract.js这两个库之上,而我之前就在浏览器中用过它们来实现类似的功能<a href="https://simonwillison.net/2024/Mar/30/ocr-pdfs-images/">。</a>
LiteParse之所以没有浏览器版本,唯一的理由是之前没人做过……
<h4 id="introducing-liteparse-for-the-web">LiteParse for the web上线啦</h4>
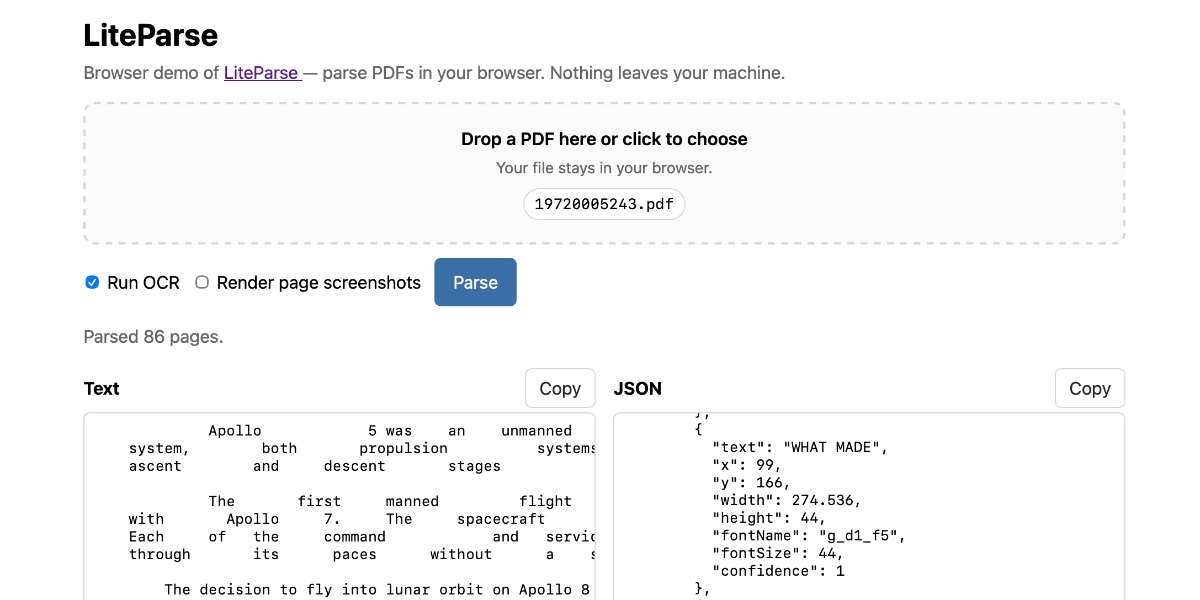
访问<a href="https://simonw.github.io/liteparse/">https://simonw.github.io/liteparse/</a>,即可在你的浏览器中直接尝试LiteParse处理任意PDF文件。以下是它的界面效果:
<p><img alt="LiteParse浏览器演示网页的截图。标题为“LiteParse”,副标题为“LiteParse的浏览器演示——在你的浏览器中解析PDF文件。数据不会离开你的设备。”一个虚线边框的拖放区域写着“将PDF文件拖入此处或点击选择 / 文件会保留在你的浏览器中。”并有一个标记为“19720005243.pdf”的文件标签。下方是一个勾选的“运行OCR”复选框、一个未勾选的“渲染页面截图”复选框,以及一个蓝色的“解析”按钮。状态文本显示:“已解析86页。”随后是两个并排的面板。左侧面板标题为“文本”,带有一个复制按钮,显示等宽字体的提取文本,开头为“阿波罗5号是一艘无人驾驶系统,包括上升段和下降段的推进系统”。右侧面板标题为“JSON”,同样带有复制按钮,包含JSON格式数据,显示每段文本的尺寸、位置及检测到的字体信息。” src="https://static.simonwillison.net/static/2026/liteparse-web.jpg" /></p>
<p>该工具可以在不运行OCR的情况下工作,也可以选择性地在页面下方显示PDF每一页的图像。</p>
<h4 id="building-it-with-claude-code-and-opus-4-7">使用Claude Code和Opus 4.7构建它</h4>
<p>这个项目的开发始于我在iPhone上的常规Claude应用。我想亲自试试LiteParse,于是上传了一个我恰好存放在手机上的随机PDF文件,并附上如下提示:</p>
<blockquote>
<p><code>克隆 https://github.com/run-llama/liteparse 并用这个文件测试一下</code></p>
</blockquote>
<p>如今,普通Claude聊天可以直接从GitHub克隆项目;尽管默认情况下它无法访问容器中的大部分互联网资源,但可以安装PyPI和npm上的包。</p>
<p>我经常用这种方式在手机上尝试新的开源软件——这是一种无需坐下来用笔记本电脑就能快速体验新工具的方法。</p>
<p>你可以在 <a href="https://claude.ai/share/44a5ed86-e5b5-4e14-90be-1eba1e0acd13">这个共享的Claude对话记录</a> 中查看我的完整交流过程。我问了一些关于其工作原理的问题,然后又问:</p>
<blockquote>
<p><code>这个库能在浏览器中运行吗?它可以吗?</code></p>
</blockquote>
<p>这个回答让我足够确信值得真正尝试让它在浏览器中运行。于是我打开笔记本电脑,切换到了Claude Code。</p>
<p>我在GitHub上fork了原始仓库,本地克隆了一份代码,新建了一个名为web的分支,并将Claude的最后一条回复粘贴进一个名为<a href="https://github.com/simonw/liteparse/blob/web/notes.md">notes.md</a>的新文件中。接着我对Claude Code说:</p>
<blockquote>
<p><code>让这个项目变成一个网页应用程序。当加载index.html时,应该呈现一个让用户能在浏览器中打开PDF、选择OCR或非OCR模式并执行解析的应用程序。阅读notes.md以了解这个问题的初步研究,然后写出plan.md,列出详细的实现计划</code></p>
</blockquote>
我总是喜欢为这类项目制定计划。有时我会使用Claude的“规划模式”,但这次我知道自己希望将计划作为仓库中的一个文件,因此我直接让它生成<code>plan.md</code>。
这也意味着我可以和Claude一起迭代这个计划。我发现Claude决定跳过生成PDF中图片的截图,并建议将“canvas编码交换”推迟到v2版本。我通过如下提示修复了这个问题:
<blockquote>
<p><code>更新计划,说明我们将执行canvas编码交换,以确保截图功能正常工作</code></p>
</blockquote>
经过几次简短的后续提示后,我得到了一份我认为足够完善、可以开始实现的<a href="https://github.com/simonw/liteparse/blob/web/plan.md">plan.md</a>。
我输入了如下提示:
<blockquote>
<p><code>构建它。</code></p>
</blockquote>
然后基本上就让Claude Code自行处理,我转而去忙其他项目,刷了刷Duolingo,偶尔查看一下进展。
我在工作过程中又添加了一些提示到队列中。这些提示目前还没有出现在我导出的对话记录里,但其实只要在相关的<code>~/.claude/projects/</code>文件夹下运行<code>rg queue-operation --no-filename | grep enqueue | jq -r '.content'</code>命令,就能提取出来。
以下是几个关键的后续提示及一些备注:
<ul>
<li>
<code>实现时请使用Playwright和红绿TDD,也把这部分计划好</code> — 我已经写过更多关于红绿TDD的内容,详见<a href="https://simonwillison.net/guides/agentic-engineering-patterns/red-green-tdd/">这里</a>。</li>
<li>
<code>我们使用PDF.js自带的渲染器</code>(之前它在尝试用pdfium)</li>
<li>
<code>最终的UI应该同时包含文本和格式化后的JSON输出,两者都放在textarea中,并且都有复制到剪贴板的按钮——还要适配移动端</code> —— 我有了一个新的UI设计思路。</li>
<li>
<code>途中提交小的commit</code> —— 见下文。</li>
<li>
<code>确保index.html页面顶部包含一个指向https://github.com/run-llama/liteparse的链接</code> —— 在这种项目中,给依赖项正确署名非常重要!</li>
<li><code>“View on GitHub”这个文案不好,因为这不是包含这个网页应用的仓库,而是底层LiteParse库对应的网页应用</code></li>
<li><code>OCR功能默认应处于未勾选状态</code></li>
<li>
<code>当我尝试在浏览器中解析PDF时看到错误信息:'Parse failed: undefined is not a function (near '...value of readableStream...')' —— 它是在Chrome中用Playwright测试的,结果发现是Safari的一个bug</code></li>
<li><code>……哦,这在Safari里会出现,但在Chrome里没问题</code></li>
<li><code>点击“复制”按钮后,文字应变为“已复制!”并持续1.5秒</code></li>
<li>
<code>[图像 #1] 样式化文件输入框,避免长文件名在Firefox上导致布局错乱——事实上,加入一个拖拽区域UI,也可以点击来选择文件</code> —— 拖入一些小UI瑕疵的截图,效果居然意外地好。</li>
</ul>
<li><code>调整拖放区域,使文本垂直居中,目前它稍微偏上了一些</code></li>
<li>
<code>在 macOS 上的 Safari 中会出错,Chrome 和 Firefox 都能正常工作。在 Safari 中点击“解析”按钮后(未勾选 OCR 时),我看到提示“Parse failed: undefined is not a function (near '...value of readableStream...')”,问题依然存在...</code></li>
<li>
<code>现在 Safari 已经可以正常运行了</code>——但一旦我指出这个问题,他们很快就修复了,让 Playwright 能够在该浏览器中正常工作。</li>
</ul>
<p>我开始习惯性地要求“逐步提交小改动”,因为这样能让代码更易理解和后续审查,我也有一种未经证实的直觉:这或许也能让代理更高效地工作——这又是一个鼓励分步规划、一次解决一个问题的信号。</p>
<p>当项目运行起来之后,我决定最好能和正在开发中的版本进行交互。我另外开启了一个针对同一目录的 Claude Code 会话,询问如何运行这个应用,它建议使用 <code>npx vite</code>。执行该命令后启动了一个带有热重载功能的开发服务器,这意味着我可以立刻看到每次修改对磁盘文件的影响,并继续提出进一步的调整或修复请求。</p>
<p>临近结尾时,我决定这个版本已经足够发布。我新建了一个 Claude Code 实例并告诉它:</p>
<blockquote>
<p><code>查看 web/ 文件夹,为这个仓库设置 GitHub Actions,使得每次推送都运行测试;如果测试通过,则部署构建后的 Vite 应用到 GitHub Pages,确保 web/index.html 是部署后页面的 index.html,并且能在 GitHub Pages 正常访问。</code></p>
</blockquote>
<p>经过进一步迭代,最终形成了如下 GitHub Actions 工作流:<a href="https://github.com/simonw/liteparse/blob/web/.github/workflows/deploy-web.yml">这里</a> 使用 Vite 构建应用并将结果部署到 <a href="https://simonw.github.io/liteparse/">https://simonw.github.io/liteparse/</a>。</p>
<p>我很喜欢用 GitHub Pages 来部署这类项目,因为它可以快速配置(比如由 Claude 完成)——只需几行设置就能把任意仓库变成一个可部署的网页应用,零成本,还能支持任何必要的构建步骤。甚至私有仓库也适用,只要你不介意唯一的保护措施是隐藏 URL。</p>
<p>对于这种项目,总存在一个重大风险:模型可能会“作弊”——将关键功能标记为“TODO”并伪造实现,或者绕过初始需求采取捷径。</p>
<p>防止这种情况的负责任做法是审查所有代码……但这个项目并非为此设计,所以我启用 OpenAI Codex 并使用 GPT-5.5(我有预览权限),然后让它回答:</p>
<blockquote>
<p><code>描述 Node.js 命令行工具和 web/ 版本之间的运行差异</code></p>
</blockquote>
<p>我得到的回答让我确信 Claude 没有采取任何可能危及项目的捷径。</p>
……就这么多了。在Claude Code中完成这个“构建”步骤的总耗时为59分钟。我使用了<a href="https://github.com/simonw/claude-code-transcripts">claude-code-transcripts</a>工具导出了完整对话的可读版本,你可以<a href="https://gisthost.github.io/?d64889bfc1b897fea3867adfec62ed89/index.html">在这里查看</a>,尽管缺少那些额外排队的提示(我已提交了一个<a href="https://github.com/simonw/claude-code-transcripts/issues/98">问题来修复这一点</a>)。
<h4 id="is-this-even-vibe-coding-any-more-">这还是所谓的“氛围编程”吗?</h4>
<p>我对<a href="https://simonwillison.net/2025/Mar/19/vibe-coding/">“氛围编程”的原始定义非常较真</a>——氛围编程并不意味着你只要用AI帮你写代码就叫氛围编程,它特指你在完全不查看、也不关心生成代码的情况下使用AI。</p>
<p>按照我自己的定义,这个LiteParse for the web项目几乎就是最纯粹的氛围编程!我甚至没有看过项目中生成的任何一行HTML或TypeScript代码——事实上,在写下这句话时,我还得去确认一下它是用了JavaScript还是TypeScript。</p>
<p>但不知为何,这次项目却不像我其他一些氛围编程作品那样让我感到强烈的“氛围感”:</p>
<ul>
<li>作为一个静态的浏览器内Web应用托管在GitHub Pages上,任何错误的影响范围几乎可以忽略不计:要么你的PDF能正常解析,要么不能。</li>
<li>没有任何私有数据被传输到外部——所有处理都在你的浏览器中完成,因此无需安全审计。我曾在运行时快速看了一眼网络面板,发现当PDF被解析时并未发起额外请求。</li>
<li>即便如此,要以这种方式使用模型,仍然需要大量工程经验和知识。识别出将LiteParse移植到浏览器直接运行是整个项目的关键所在。</li>
</ul>
<p>最重要的是,我很乐意把我的声誉和这个项目绑定在一起,并推荐其他人也尝试一下。与其他大多数氛围编程工具不同,我不认为投入更多工程时间能让这个项目的初始版本变得显著更好。它现在这样就很好!</p>
<p>我还没有向<a href="https://github.com/run-llama/liteparse">原始仓库</a>提交Pull Request,因为我还没跟LiteParse团队讨论过这件事。我已提交了一个<a href="https://github.com/run-llama/liteparse/issues/147">问题</a>,如果他们希望把这个氛围编程实现作为更正式功能的基础,他们可以随意拿去用。</p>
标签:javascript,ocr,pdf,projects,ai,generative-ai,llms,vibe-coding,coding-agents,claude-code,agentic-engineering
来源与参考
收录于 2026-04-24