微软发布VibeVoice:带说话人分离的开源语音转文字模型
Simon Willison··作者 Simon Willison
关键信息
该模型在处理时最多需30GB内存,超过一小时的音频必须分段处理;默认最大token数(8192)限制了约25分钟的转录,除非手动增加。输出为包含说话人ID的JSON格式,便于通过Datasette Lite等工具分析。
资讯摘要
微软于2026年1月21日发布了VibeVoice,这是一个新的开源语音转文字模型,内置说话人分离功能并采用MIT许可证。西蒙·威尔森用MLX和mlx-audio在Mac上测试了它,将一段99.8分钟的播客转录用了524秒(约8分45秒)。该模型正确识别出三位说话人——包括两个利尼·拉奇茨基的声音版本——并生成结构化的JSON输出。
峰值内存使用量为30.44GB,但活动监视器显示预处理阶段更高。用户必须调整--max-tokens参数以处理更长的音频,因为默认值仅允许约25分钟的转录。这使得VibeVoice成为开发者寻求本地、准确且具备说话人识别能力的转录工具的理想选择。
资讯正文
VibeVoice 是微软推出的语音转文字模型,类似于 Whisper,采用 MIT 许可协议,并内置了说话人辨识功能。
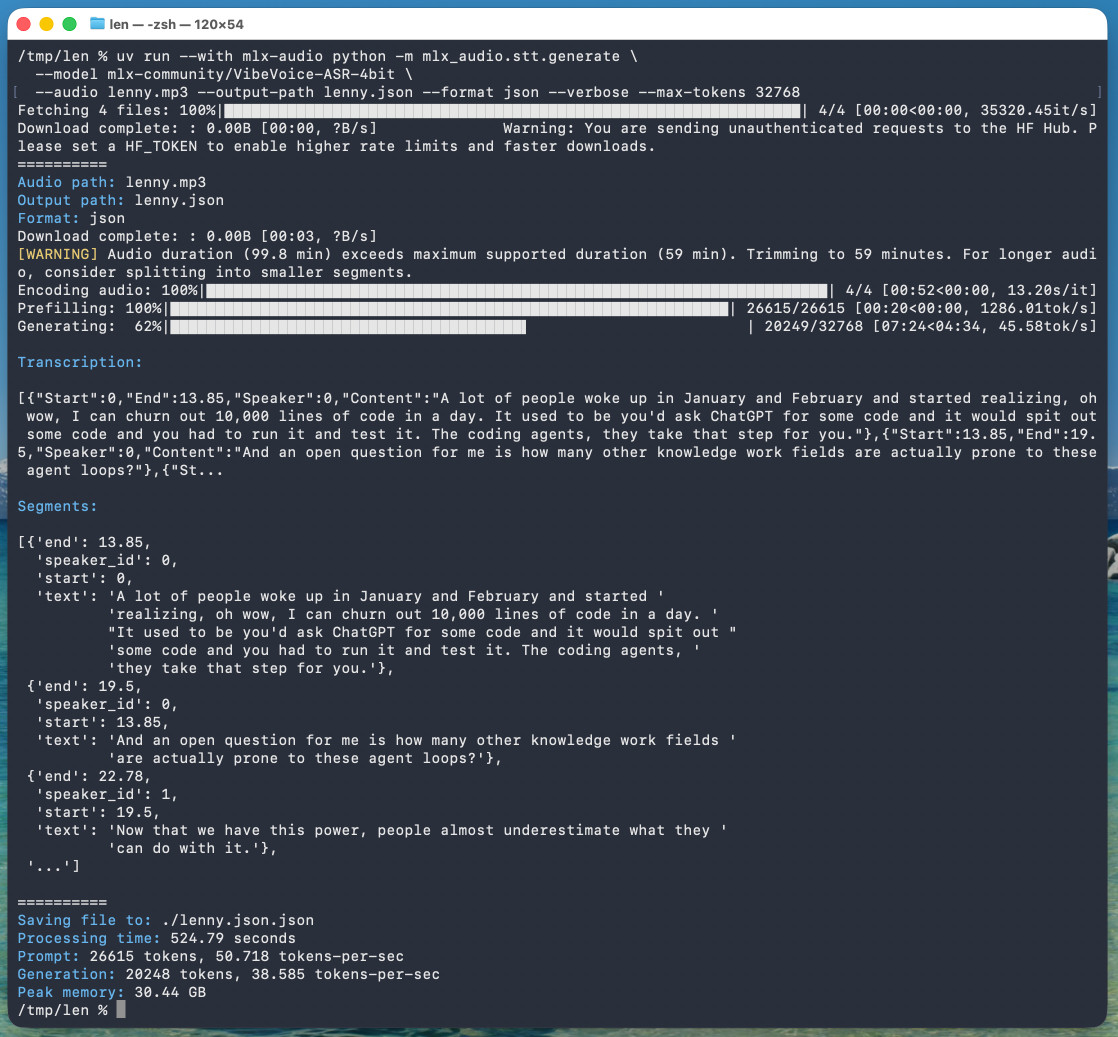
微软于 2026 年 1 月 21 日发布了该模型,但我直到今天才尝试使用。以下是在 Mac 上用 uv 工具、Prince Canuma 开发的 mlx-audio 库,以及 5.71GB 的 mlx-community/VibeVoice-ASR-4bit 模型(这是对原版 17.3GB 的 VibeVoice-ASR 模型进行 MLX 转换的结果)运行该模型的命令行指令,用于处理我最近与 Lenny Rachitsky 的播客录音文件(已下载):
uv run --with mlx-audio mlx_audio.stt.generate \
--model mlx-community/VibeVoice-ASR-4bit \
--audio lenny.mp3 --output-path lenny \
--format json --verbose --max-tokens 32768
工具返回了如下结果:
Processing time: 524.79 seconds
Prompt: 26615 tokens, 50.718 tokens-per-sec
Generation: 20248 tokens, 38.585 tokens-per-sec
Peak memory: 30.44 GB
这意味着处理一小时音频耗时约 8 分 45 秒(在配备 128GB 内存的 M5 Max MacBook Pro 上运行)。
我测试过 .wav 和 .mp3 文件,两者都能正常工作。
如果省略 --max-tokens 参数,默认值为 8192,大约能处理 25 分钟的音频。我通过反复试验发现这个限制,于是将它扩大四倍以确保能完整提取整小时内容。
该命令报告峰值内存使用量为 30.44GB,但在活动监视器中观察到预填充阶段使用了约 61.5GB,生成阶段则约为 18GB。
这是输出的 JSON 文件:<a href="https://gist.github.com/simonw/d2c716c008b3ba395785f865c6387b6f">点击查看</a>。其核心结构如下:
{
"text": "And an open question for me is how many other knowledge work fields are actually prone to these agent loops?",
"start": 13.85,
"end": 19.5,
"duration": 5.65,
"speaker_id": 0
},
{
"text": "Now that we have this power, people almost underestimate what they can do with it.",
"start": 19.5,
"end": 22.78,
"duration": 3.280000000000001,
"speaker_id": 1
},
{
"text": "Today, probably 95% of the code that I produce, I didn't type it myself. I write so much of my code on my phone. It's wild.",
"start": 22.78,
"end": 30.0,
"duration": 7.219999999999999,
"speaker_id": 0
}
由于这是一个对象数组,我们可以用 Datasette Lite 打开它:<a href="https://lite.datasette.io/?json=https://gist.github.com/simonw/d2c716c008b3ba395785f865c6387b6f#/data/raw?_facet=speaker_id">在线浏览</a>,便于查阅。
有趣的是,Datasette Lite 显示出三位说话者——它识别出了我和 Lenny 的对话,还单独识别出一个 Lenny,这是他用来朗读开场白和赞助商广告的声音!
VibeVoice最多只能处理一小时的音频,因此上面的命令只转录了播客的前一个小时。如果要转录更长时间的内容,你需要将音频分割,最好在各段之间保留约一分钟的重叠部分,以避免在分割点因单词转录不完整而产生错误。此外,你还需将多个片段中的发言人ID对齐。
标签:
微软、Python、Datasette Lite、uv、mlx、Prince Canuma、语音转文字
来源与参考
收录于 2026-04-29