Know3D利用文本提示控制3D物体的隐藏面
The Decoder··作者 Jonathan Kemper
关键信息
该系统使用Qwen2.5-VL(语言模型)、Qwen-Image-Edit(图像生成器)和微软Trellis.2(3D生成器),其中图像生成器的中间状态对引导3D输出最为有效。
资讯摘要
从单张图像生成完整3D对象时,AI模型必须猜测可见面背后的内容——这常常导致不现实或不准确的结果。Know3D通过利用大型语言模型的世界知识来解决这个问题,方法是根据文本提示进行推理。它不是直接将语言模型输出送入3D生成器,而是插入一个图像生成器作为翻译器。关键在于,它提取的是图像生成器的内部中间状态而非最终像素,从而保留了语义信息和空间结构。
这种方法避免了因图像生成错误而影响3D结果的问题。该方法在咖啡杯、椅子和房屋等不同物体上进行了测试,展示了几何一致性,同时根据文本指令调整隐藏面。它在HY3D-Bench基准测试中表现优异,尤其是在语义准确性和背面几何质量方面优于现有方法。
资讯正文
Know3D 让用户通过文本提示控制 3D 对象的隐藏背面
一个研究团队利用大型语言模型的知识,在从单张图像生成 3D 对象时,通过文本控制对象背面,解决了 3D 生成中的一个根本性问题。
当 AI 模型必须从一张照片构建完整的 3D 对象时,它面临一个重大盲区:图像只显示了一面,因此模型基本上只能猜测背后的内容。根据来自中国多所大学团队的一篇新论文,这种情况经常导致物理上不合理的形状,或者生成结果与用户意图不符。
问题源于数据。相比于互联网上庞大的图像和文本数据集,3D 训练数据仍然难以获取。3D 模型在训练中吸收的世界知识还不足以可靠地填补隐藏部分。
Know3D 通过引入多模态语言模型的广泛世界知识来解决这个问题。用户可以输入一段文本描述,说明他们看不到的那一侧应该呈现什么内容。
图像生成器架起了语言与 3D 之间的桥梁
研究人员表示,直接将语言模型的输出输入到 3D 网络的做法实际上行不通。因为这些表示过于抽象,缺乏足够的空间信息以生成可用的几何结构。
因此,Know3D 采取了迂回策略,在语言模型和 3D 生成器之间插入一个图像生成模型作为翻译工具。该系统使用 Qwen2.5-VL 作为语言模型,Qwen-Image-Edit 进行图像生成,以及微软的 Trellis.2 作为 3D 生成器。
语言模型读取文本指令并分析输入图像,随后图像生成器将这种理解转化为空间结构信息,从而引导 3D 生成器。
关键在于确定从图像生成器中提取哪些信息。团队测试了三种方案:在最终输出前获取内部图像表示、通过 Meta 的 DINOv3 提取图像特征,以及模型生成过程中的内部中间状态。最后一个选项明显胜出——这些中间状态既包含语义信息也包含空间信息,而无需依赖像素级精度或最终图像中的错误。
模型内部状态可防止错误扩散
这在实践中非常重要。如果图像生成器产生错误的背面视图(例如,把单肩包画成两条肩带),基于图像的方法会直接将这个错误传递给 3D 输出。
而模型的内部中间状态更具容错性:它们似乎保留了足够的空间和语义信息,仍能生成稳固的 3D 对象。即使在处理中途,模型似乎也能建立起相当可靠的结构和形态感。
团队切入这些状态的时间点同样重要。切入太早,信息过于聚焦于像素细节;切入太晚,噪声就会占据主导。他们的消融实验表明,在整个流程的大约四分之一处获取状态是最理想的平衡点。
Know3D 让用户通过文本提示控制 3D 物体隐藏背面
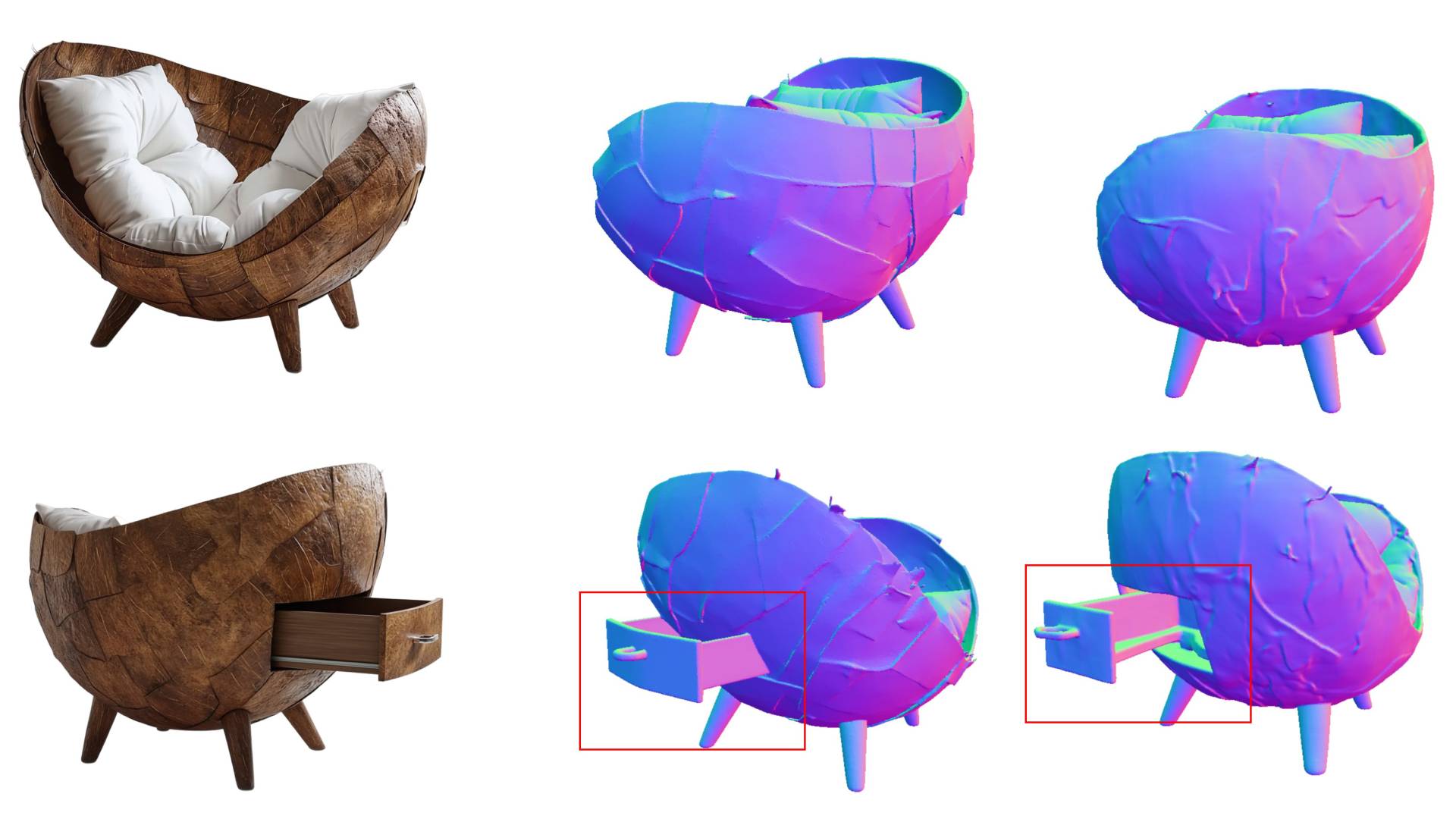
Know3D 相比现有方法的主要优势在于其提供的控制程度。研究人员用一个咖啡杯进行了演示:相同的输入照片,根据不同的文本指令,会生成几何上一致但不同的背面。这一原理同样适用于椅子、机器人和房屋:背面会根据描述进行调整,而可见的正面则保持不变。
基准测试成绩优异,但结果取决于基础模型
Know3D 在 Hunyuan3D 团队构建的 HY3D-Bench 基准测试中取得了最佳的语义匹配分数,该测试衡量输入图像与生成 3D 对象之间的匹配度。这一表现优于当前所有单图生成方法,也优于将生成的背面视图作为第二张输入图像的方法。研究人员表示,Know3D 在背面几何质量方面也优于竞争对手。
研究人员指出,最终结果的好坏取决于底层语言模型是否正确理解了文本指令。如果模型误解了提示,生成的 3D 结果也会偏离预期。因此,更强的多模态模型未来有望减少这类问题。
AI 新闻无炒作 —— 由人类精选
来源与参考
收录于 2026-04-05