模型量化与浮点表示的交互式指南
Simon Willison··作者 Simon Willison
关键信息
文章使用可视化工具展示float32数字如何以二进制格式存储(符号、指数、尾数),并演示从16位到8位量化对模型质量影响极小,而从16位到4位则性能下降至原始水平的约90%。异常值有时会被保留未量化或单独存储以防止退化。
资讯摘要
萨姆·罗斯最新的交互式文章深入探讨了模型量化——一种通过降低权重精度来压缩大型语言模型的技术。文章使用颜色编码的位字段和实时滑块直观解释IEEE 754单精度浮点数。它揭示了稀有的‘异常值’权重虽然数量少,却是保持模型输出质量的关键。
文章使用困惑度和GPQA基准测试评估了Qwen 3.5 9B模型的量化效果,显示从16位到8位量化几乎不影响准确率,而从16位到4位则导致约10%的性能下降。实际量化方案通常会单独处理这些异常值以避免灾难性失败。
资讯正文
量化从零开始
Sam Rose继续他发布极具信息量的交互式文章的势头,这次解释了大型语言模型的量化是如何工作的(他说这可能是“我写过的最好的一篇文章”)。
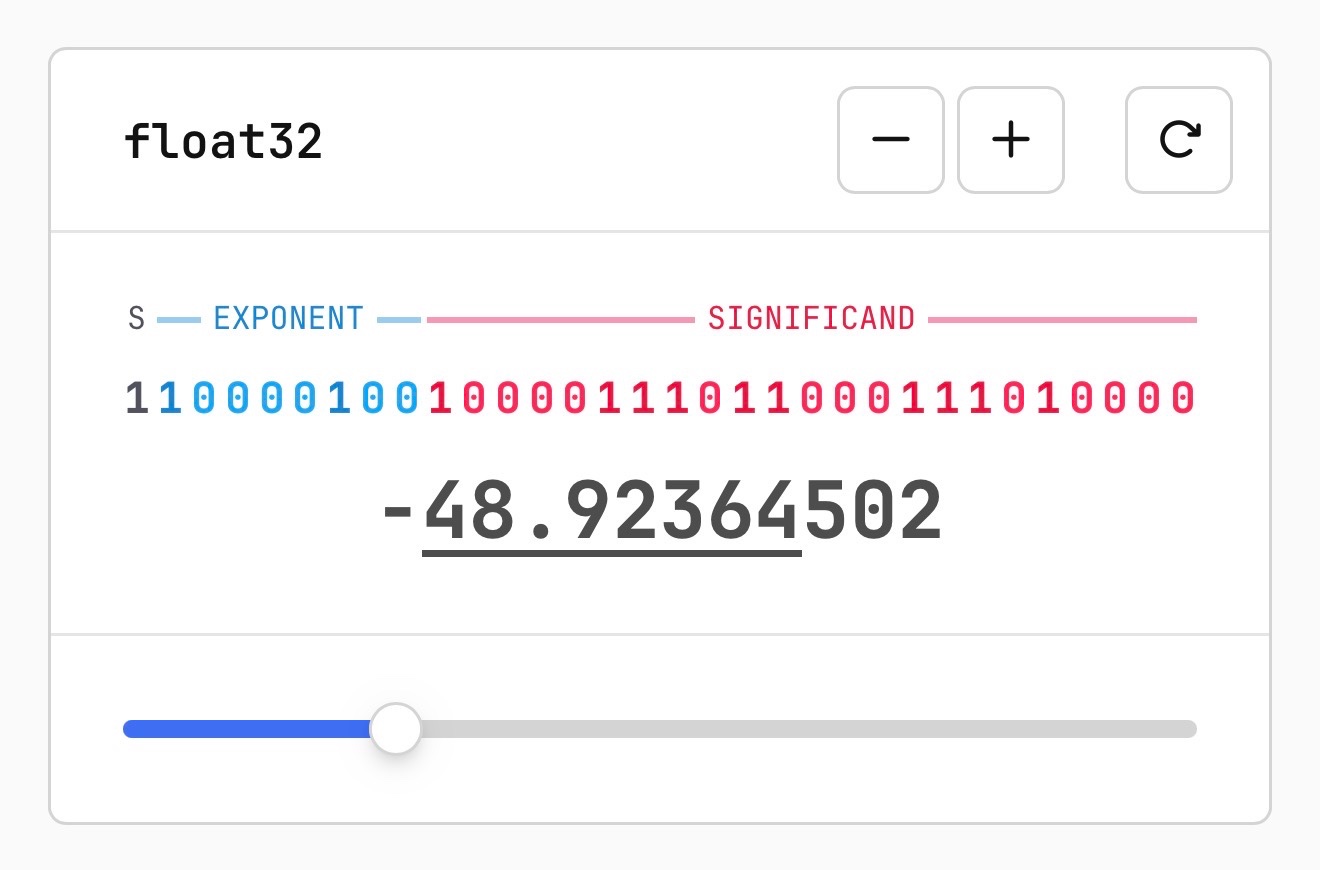
文章还包含了我见过的关于浮点数如何用二进制位表示的最佳可视化说明。
<img alt="一个交互式float32二进制表示工具的截图,显示值为-48.92364502,颜色编码的位字段标注为S(符号)、EXPONENT(蓝色)和SIGNIFICAND(粉色),显示32位模式11000010010000111101100001110100000,并配有底部滑块控件以及减号、加号和重置按钮。" src="https://static.simonwillison.net/static/2026/float.jpg" />
我之前从未听说过量化中的<strong>异常值</strong>——即存在于正常小数值分布之外的罕见浮点值——但显然它们非常重要:
<blockquote>
<p>为什么这些异常值存在? [...] 简而言之:没人能确定,但其中一小部分异常值对模型质量至关重要。即使移除一个“超级权重”(Apple称之为这种权重),也可能导致模型输出完全无意义的内容。</p>
<p>鉴于它们的重要性,实际的量化方案有时会额外工作来保护这些异常值。它们可能会选择完全不量化这些值,或者将它们的位置和数值保存到单独的表中,然后再将其移除,以避免破坏其所在的块。</p>
</blockquote>
此外还有关于<a href="https://ngrok.com/blog/quantization#how-much-does-quantization-affect-model-accuracy">量化对模型准确性的影响有多大?</a>的一节内容。Sam解释了<strong>困惑度(perplexity)</strong>和<strong>KL散度(KL divergence)</strong>的概念,然后使用<a href="https://github.com/ggml-org/llama.cpp/tree/master/tools/perplexity">llama.cpp困惑度工具</a>和GPQA基准测试运行结果,展示了不同量化级别如何影响Qwen 3.5 9B模型的表现。
他的结论是:
<blockquote>
<p>看起来从16位降到8位几乎不会造成质量损失。从16位降到4位则更明显一些,但绝不是原模型的四分之一那么差,大约在90%左右,具体取决于你如何衡量。</p>
</blockquote>
来源与参考
收录于 2026-03-27