Gemini 把多模态视频生成与智能体编码推到台前
Google 展示 Gemini Omni 和 Gemini 3.5 的九个演示,重点是可对话编辑的视频生成和长周期智能体任务能力,进一步把前沿模型往产品化工具推进。
AI 日报
今天的核心主题很清晰:AI 不再只是展示“能做什么”,而是在医院、企业、基础设施和安全体系中加速落地。与此同时,成本控制、权限治理和风险评估也同步变成了绕不开的主线。开发者、企业和公共机构都在同一时间面对一个问题:如何把更强的 AI 变成可控、可持续、可验证的生产力。
Overview
从 51 条资讯中筛选出 20 条
今天的核心主题很清晰:AI 不再只是展示“能做什么”,而是在医院、企业、基础设施和安全体系中加速落地。与此同时,成本控制、权限治理和风险评估也同步变成了绕不开的主线。开发者、企业和公共机构都在同一时间面对一个问题:如何把更强的 AI 变成可控、可持续、可验证的生产力。
Google 展示 Gemini Omni 和 Gemini 3.5 的九个演示,重点是可对话编辑的视频生成和长周期智能体任务能力,进一步把前沿模型往产品化工具推进。
波士顿儿童医院已用 OpenAI 技术辅助罕见病诊断,OpenAI 也扩大 GPT-Rosalind 的可信访问,用于公共卫生、疫情准备和生物防御。
Groq 寻求 6.5 亿美元融资扩展推理云,XCENA 则融资 1.35 亿美元押注近内存计算,反映出市场正在围绕 AI 运行效率重新下注。
Anthropic 的 470 亿美元年化营收、Claude 5 亿美元月账单传闻,以及亚马逊刷分式 AI 榜单事件,共同说明 AI 使用已进入预算与治理时代。
OpenAI 发布可信第三方评估指南,IBM 和 Red Hat 推出 Project Lightwell,说明 AI 时代的软件安全和模型审计都在加速工程化。
两篇关于“免费清洁换训练数据”的报道显示,机器人公司正在争夺第一视角家务视频,数据采集、隐私与标注能力成为新竞争点。
2026-05-30 的报道集中展现了 AI 产业的两个方向同时加速:一边是能力持续突破,另一边是治理与成本压力迅速上升。[1][2][3] 从 Google 的 Gemini Omni、Anthropic 的营收增长,到 OpenAI 的生物防御和评估指南,再到企业内部 AI 账单、开源安全和推理基础设施融资,今天的新闻说明 AI 已经进入“规模化运营”阶段,而不只是技术演示阶段。[1][3][4][5][8][13][19][20]
Google 在 I/O 上展示 Gemini Omni 与 Gemini 3.5 的九个演示,重点放在多模态视频生成、对话式编辑、智能体任务和编码能力上。[1] 这类发布的信号很明确:前沿模型正在向可用工具靠拢,尤其会影响内容生产、自动化工作流和开发者工具链。[1]
波士顿儿童医院使用 OpenAI 技术辅助罕见病诊断,并已帮助识别 40 多例病例,说明 AI 正进入临床工作流而不只是停留在概念层。[2] 同时,OpenAI 也扩大了 GPT-Rosalind 的可信访问,用于生物防御、疫情准备、诊断和疫苗研究,显示高风险领域正在以受控方式引入前沿模型。[3][7]
Groq 据报寻求 6.5 亿美元融资以扩展推理云,XCENA 则融资 1.35 亿美元押注“内存才是真瓶颈”的芯片架构。[5][6] 这些报道共同说明,市场正在从“训练谁更强”转向“谁能更便宜、更快、更省电地运行 AI”。[5][6]
一家公司据称一个月在 Claude 上花了 5 亿美元,亚马逊则因为员工刷内部 AI 榜单而关闭 Kirorank。[19][20] 这两条新闻都指向同一个现实:AI 的采用不再只是接入模型,而是要处理配额、指标设计、成本控制和使用规范。[19][20]
OpenAI 发布可信第三方评估指南,IBM 和 Red Hat 推出 Project Lightwell 试图用 AI+工程团队处理开源漏洞洪流。[8][13] 这表明 AI 安全与软件供应链安全正在从“建议”变成“基础设施”。[8][13]
今天的报道共同说明:AI 产业正在从“能演示”转向“能部署、能收费、能治理”。未来几个月真正决定胜负的,可能不只是模型能力,而是谁能把成本、权限、评估和数据管住,同时把 AI 稳定塞进真实业务流程。[1][2][3][5][13][19][20]
Stories
Google AI Blog

Google 在 Google I/O 2026 上展示了其新的 Gemini Omni 和 Gemini 3.5 系列的九个演示。 这些演示重点展示了 Omni 的多模态视频生成与对话式编辑能力,以及 Gemini 3.5 Flash 的智能体和编码能力。
这表明生成式视频和智能体 AI 正在向前迈出重要一步,这两个方向都可能重塑创意工作流和开发者工具。 如果这些能力能够在真实产品中稳定落地,它们将影响视频编辑者、内容团队,以及所有构建自动化多步骤 AI 系统的人。
在 Google I/O 2026 上,Google 发布了两个新的模型系列:Gemini Omni 和 Gemini 3.5。 这篇文章更像是一组演示展示,而不是深入的技术论文,并给出了九个实际使用场景示例。 Gemini Omni 被描述为一个统一的多模态模型,可以接受图像、音频、视频和文本等多种输入,并生成视频。 Google 表示,该模型可以基于 Gemini 对现实世界的知识生成高质量视频,还能通过对话方式直接编辑视频。 演示强调,每一次指令都会建立在上一次的结果之上,因此人物形象保持一致,物理效果保持合理,场景也会记住之前的修改。 示例提示包括把雕塑变成泡泡,以及在已有视频基础上逐步加入更复杂的场景变化。
文章还展示了一个更复杂的递归视觉提示,说明该模型可以重构动作和环境。 在 Gemini 3.5 方面,Google 表示 3.5 Flash 把前沿智能与行动能力结合起来,专门面向长周期的智能体任务,并保持 Flash 系列一贯的速度。 演示展示了它如何在 Antigravity 的支持下执行多步骤工作流,例如自动重命名并分类非结构化资产。 Google 还表示,更新后的 Antigravity harness 可以让 3.5 Flash 在监督下部署协作式子智能体,以处理更大规模的问题和编码任务。 最后,文章指出 3.5 Flash 现在已成为全球 Gemini 应用和 Search 中 AI Mode 的默认模型,而由其智能体编码能力驱动的信息智能体将先面向 Google AI Pro 和 Ultra 订阅用户,在今年夏天上线。
Gemini Omni 被描述为一种可以接收图像、音频、视频和文本作为输入,并生成基于知识的高质量视频的模型,而且可以通过自然语言对话进行编辑。 Gemini 3.5 Flash 被定位为适合长周期智能体任务和编码的快速模型,Google 还表示它现在已在全球范围内为 Gemini 应用和 Search 中的 AI Mode 提供支持。
OpenAI News
波士顿儿童医院正在使用 OpenAI 技术来改善患者护理并减轻行政负担。该院表示,这套系统已经帮助诊断了 40 多例罕见病病例。
这是 AI 从通用工具进入临床工作流程的一个具体案例,它可能帮助医生更快识别难以诊断的疾病。对于罕见病患儿来说,即使只是诊断支持上的小幅提升,也可能显著影响治疗路径和家庭结果。
波士顿儿童医院表示,正在使用 OpenAI 技术来改善患者护理、减轻行政负担,并辅助罕见病诊断。该院称,这套系统已经帮助识别出 40 多例罕见病病例,显示出 AI 在高要求临床环境中的实际应用价值。与其说这是一项独立的技术突破,不如说这是 AI 在既有医院工作流程中的落地部署。这个应用场景对罕见病尤其重要,因为这类疾病往往诊断缓慢且复杂,单个病例可能很少见,也不容易被医生立即识别。
通过为临床决策提供支持,这项技术旨在更快、更省力地帮助医生提出可能的诊断方向。医院同时强调了运营层面的收益,说明 AI 不仅用于临床,也用于减轻行政工作负担。整体来看,这条新闻更强调 OpenAI 工具在医疗领域的真实采用,而不是发布新的模型。它也反映出越来越多医院正在尝试用 AI 提升效率和诊断支持能力。
这项公告把 OpenAI 定位为同时支持运营效率和临床决策,而不是取代医生。罕见病场景也符合临床决策支持系统的用途,即在诊断过程中帮助医生将患者信息与医学知识进行匹配。
OpenAI News
OpenAI 推出了 Rosalind Biodefense,向经过审核的开发者和美国政府合作伙伴扩大了对 GPT-Rosalind 的可信访问。该项目面向生物防御、公共卫生和疫情防备相关工作。
这意味着前沿 AI 模型被引入一个高度受控、但影响极大的领域,在这里早期检测、准备和响应都可能非常关键。它也表明 OpenAI 将生物安全视为先进 AI 的重要落地场景,而不只是研究用途。
OpenAI 宣布推出 Rosalind Biodefense,作为对 GPT-Rosalind 可信访问范围的进一步扩大。该项目面向经过审核的开发者以及美国政府合作伙伴,聚焦生物防御、公共卫生和疫情防备。OpenAI 表示,其目标是帮助可信用户将前沿 AI 能力用于已经产品化、可实际运作的生物防御工具,从而在下一次生物威胁出现前提升准备能力。公司还表示,将为参与开发者资助 GPT-Rosalind 的访问并提供启动支持。
搜索结果显示,这一发布于 2026 年 5 月 29 日被报道。相关报道将 GPT-Rosalind 描述为 OpenAI 面向生命科学的前沿推理模型,如今被用于更实际的防御场景。整体来看,这一举措强调的是在严格控制下增强社会韧性,而不是面向大众开放使用。
访问范围仅限于经过审核的开发者和美国政府合作伙伴,OpenAI 还表示将资助 GPT-Rosalind 的使用并提供启动支持。重点是可投入实际运作的生物防御工具,而不是开放式使用模型。
Simon Willison
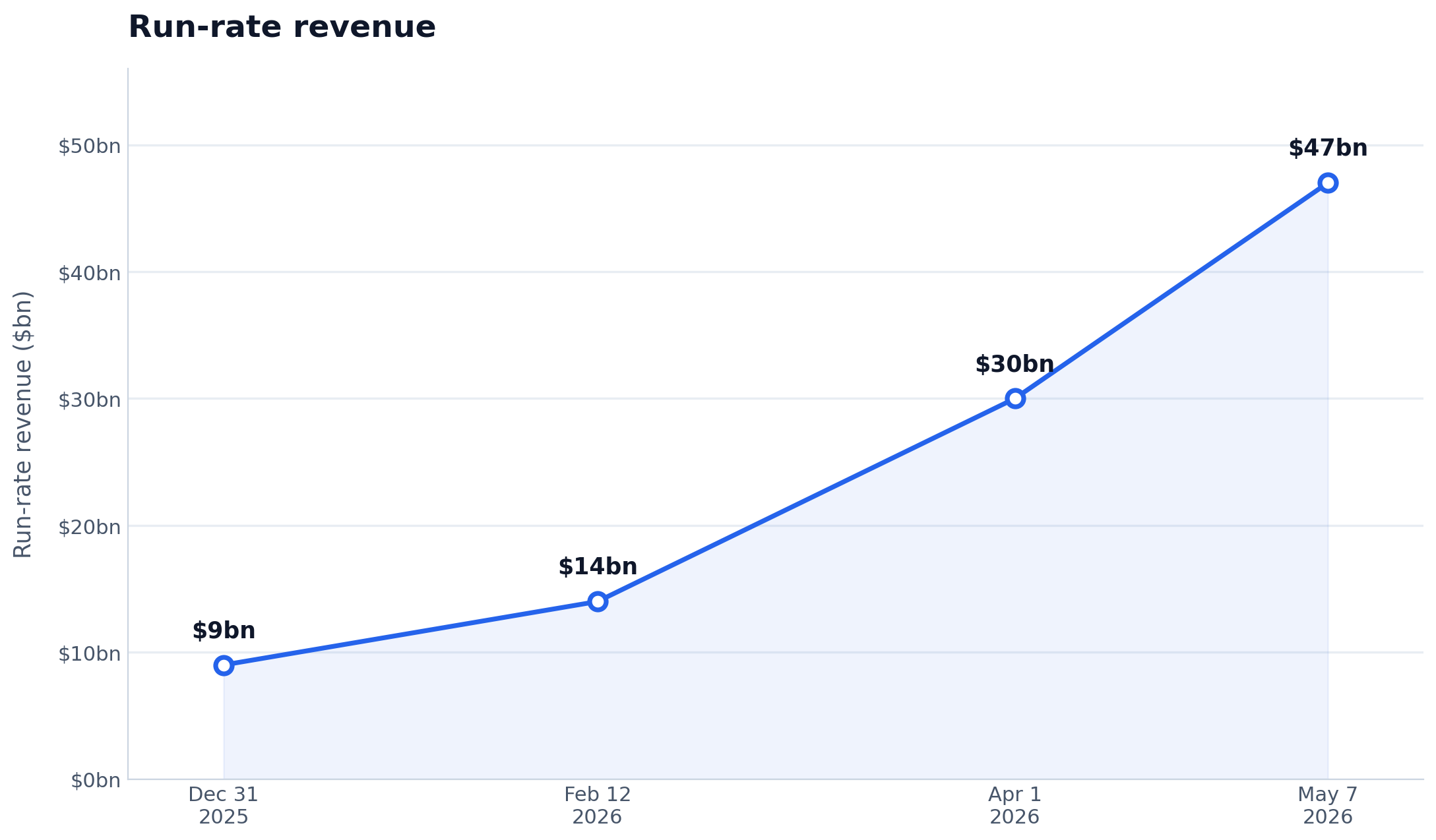
在其 Series H 融资公告中,Anthropic 表示其 run-rate revenue 在本月早些时候突破了 470 亿美元。Simon Willison 指出,这一数字相比 Anthropic 在 4 月披露的 300 亿美元和 2 月披露的 140 亿美元都有明显跃升。
470 亿美元的年化营收跑速,表明企业 AI 采用正在以极快速度扩张,尤其对于行业领先的模型提供商而言更具信号意义。它也使 Anthropic 的商业增长成为整个 AI 行业,以及评估市场可持续性的投资者所关注的重要基准。
Simon Willison 的文章聚焦于 Anthropic 650 亿美元 Series H 融资公告中的一句话:公司称其 run-rate revenue 在本月早些时候突破了 470 亿美元。文章指出,Anthropic 似乎已经形成了一个习惯,即在融资公告中披露这种年化营收指标。作者解释说,run-rate revenue 通常是用最近一个月的收入乘以 12 得出的年化估算值。随后,他把这次的新数字与 Anthropic 今年早些时候披露的数据进行了对比。
2026 年 2 月,Anthropic 说其 run-rate revenue 为 140 亿美元;到 2026 年 4 月,这一数字已超过 300 亿美元,而 2025 年底大约只有 90 亿美元。文章还附上一张图,直观展示了该指标从 90 亿美元、140 亿美元、300 亿美元一路快速攀升到 470 亿美元。作者同时提到 Axios 的相关报道以及 Ed Zitron 对 300 亿美元数字的质疑,用来强调这种增长速度的罕见性。Willison 认为,单纯因为数字来自 Anthropic 就怀疑其真实性并不成立,因为这些数字是在重大融资场景中披露的,而且如果未来公司提交 IPO 文件,真实数据也很可能会被公开验证。
这个数字是 run-rate 估算,意思是基于近期收入推算出的年化值,而不是完整财年的实际营收。文章还指出,这一数字出现在融资公告中,作者认为这会降低故意夸大的可能性,因为这些说法是对参与 650 亿美元 Series H 融资的投资者披露的。
TechCrunch AI

据报道,Groq 正在向现有投资者寻求 6.5 亿美元新融资,以扩大其推理云业务。此举发生在去年 12 月与 Nvidia 达成的一项据称价值 200 亿美元的“非收购”交易之后,该交易涉及部分高管离职以及将 Groq 的硬件技术授权给 Nvidia。
这轮融资表明,随着 AI 使用规模扩大,推理基础设施已经成为投资者持续看好的方向。它也显示出像 Groq 这样的初创公司,正在围绕专用芯片和云服务布局,而不仅仅是与模型训练硬件竞争。
据 Axios 报道,Groq 正在向现有投资者寻求 6.5 亿美元的新融资。该公司正在加码其推理云业务,这项业务建立在自研 AI 芯片及相关系统之上。其目标客户是需要托管高推理负载应用的开发者和企业。文中指出,推理是 AI 提示词输入之后发生的计算过程,而当前 AI 领域对推理的需求已经大于对模型训练的需求。此次融资发生在去年 12 月 Groq 与 Nvidia 达成一项重大“非收购”协议之后,据称该协议估值高达 200 亿美元。
报道提到,这项交易包含部分 Groq 高管离职加入 Nvidia,以及 Nvidia 获得 Groq 硬件技术授权。Axios 表示,这笔交易对 Groq 投资者有利,因为他们获得了现金回报,而且如果这笔交易是正式收购,它本来会成为 Nvidia 最大的一笔收购。现在,这些投资者又被要求为公司下一阶段的扩张继续出资。Groq 目前的推进由临时 CEO Adam Winter 和 CFO Matt Eng 负责。Axios 还称,这轮融资在某种程度上已接近落定,因为 Disruptive 和 Infinitium 已同意在其他现有投资者不认购其按比例份额时补足资金缺口。
Axios 报道称,这轮融资实际上接近“保底”,因为支持方 Disruptive 和 Infinitium 已同意在其他现有投资者不认购其按比例份额时补足缺口。当前公司由临时 CEO Adam Winter 和 CFO Matt Eng 领导,并在推进其推理云业务。
TechCrunch AI

XCENA 完成了 1.35 亿美元的 B 轮融资,估值达到 5.7 亿美元,公司累计融资额升至 1.85 亿美元。该公司表示,其 MX1 芯片将计算能力更靠近 DRAM,以减少拖慢 AI 推理的数据搬运开销。
如果 XCENA 的方案能够规模化落地,它有望通过减少内存、CPU 和 GPU 之间不必要的数据往返,降低 AI 基础设施的成本和功耗。这对超大规模云厂商和其他大型 AI 运营方尤其重要,因为哪怕微小的效率提升,也可能带来巨额节省。
TechCrunch 报道称,XCENA 完成了 1.35 亿美元的 B 轮融资,投后估值达到 5.7 亿美元,这反映出投资者仍在积极押注 AI 基础设施效率提升方向。这家成立四年的初创公司在韩国和美国都设有办公室,其核心观点是:AI 最大的瓶颈不只是算力,而是内存数据流动。按照传统流程,一次 AI 查询会让数据先从内存到 CPU 做预处理,再到 GPU 做计算,然后再返回;而生成每个 token 时,这个过程都会重复。XCENA 认为,这种架构会迫使大量常规工作经过行业中最昂贵、最耗电的芯片,造成明显浪费。为此,公司推出 MX1 芯片,希望把计算能力更靠近 DRAM,让常见数据操作直接在内存附近完成。
XCENA 说,这样可以减少 CPU、GPU 和内存之间反复往返的数据搬运,某些场景下甚至可能把原本需要 10 台服务器的工作量压缩到 1 台。公司 CEO Jin Kim 表示,团队由来自 Samsung 和 SK Hynix 的老兵组成,目标是让内存也像 CPU 和 GPU 一样“更智能”。XCENA 重点瞄准的是 AI 推理中围绕模型运转的部分,例如预处理、KV cache 管理和缓存,而不是 GPU 最擅长的矩阵乘法。公司还称,自去年下半年以来,市场对内存解决方案的需求显著上升,其理想客户是每年在 AI 基础设施上投入数百亿美元的超大规模云厂商。MX1 目前仍是原型,计划在 2026 年底前进入三星代工厂量产,预计 2027 年开始产生收入;与此同时,公司也将 Astera Labs 和 Marvell 视为主要竞争者,并强调自己的差异化来自更大的 IP 储备和数千个 RISC-V 核心。
MX1 通过 CXL 连接到 CPU,并在内存模块内部直接处理预处理、KV cache 管理和数据缓存等任务。XCENA 表示该芯片目前仍是原型,计划在 2026 年底前进入三星代工产线量产,并预计于 2027 年开始产生收入。
The Decoder

OpenAI 已推出 Rosalind Biodefense 计划,向经过筛选的开发者和政府合作伙伴提供 GPT-Rosalind,这是一款于 4 月发布的生命科学 AI 模型。该计划面向疫情准备、诊断、疫苗研究和 DNA 筛查等用途。
这对 AI 科学研究和生物防御都很重要,因为它把专门的生物学模型交给了公共利益导向的研究人员和机构。它可能加快早期预警、流程设计和疫苗开发等防御性工作,同时也反映出人们对 AI 赋能生物风险的担忧正在上升。
OpenAI 正在推出 Rosalind Biodefense 计划,以扩大对 GPT-Rosalind 的使用范围。GPT-Rosalind 是 OpenAI 在 4 月首次推出的一款生命科学模型,目标是更好地理解分子、蛋白质、基因和疾病生物学。OpenAI 表示,这一模型相比普通 GPT 更适合帮助研究人员把假设更快地推进到实验阶段。公司将该计划定位为生物防御和疫情准备项目,而不是面向大众的通用商业发布。OpenAI 说,它会向经过审核的开发者和政府合作伙伴提供支持,应用方向包括早期预警系统、诊断和疫苗开发。
公司还表示,会承担获批团队的访问成本。OpenAI 还提到,包括 Anthropic 在内的 AI 研究者曾多次警告 AI 可能被用于生物武器,这也是推动该计划的重要原因之一。该计划建立在现有安全措施之上,面向学术、非营利、政府关联以及中小型团队开放,前提是这些团队有明确的公共利益目标。OpenAI 重点寻找能用 AI 加速或扩展防御性研究的项目,例如文献综合、流程设计、模型构建、数据整合、模拟和决策支持。现有早期合作方包括 Lawrence Livermore National Laboratory、Johns Hopkins Applied Physics Laboratory、CEPI、Fourth Eon 和 SecureDNA,说明这一计划将进入真实的研究和筛查工作流。
OpenAI 表示将承担访问成本,并支持经过审核、且具有明确公共利益目标的学术、非营利、政府关联以及中小型团队。公司重点寻找用于文献综合、流程设计、模型构建、数据整合、模拟或决策支持的项目,早期合作方包括 Lawrence Livermore National Laboratory、Johns Hopkins Applied Physics Laboratory、CEPI、Fourth Eon 和 SecureDNA。
OpenAI News
OpenAI发布了关于如何进行可信第三方前沿AI模型评估的指南。该指南重点讨论如何评估模型能力、防护措施,以及评估本身是否有效。
随着前沿模型能力不断增强,独立评估方法对于安全、治理和基准测试变得越来越重要。这份指南有助于实验室、审计方和研究人员在判断模型是否按预期运行时形成更一致的做法。
OpenAI 发布了一份名为《A shared playbook for trustworthy third party evaluations》的指南,为前沿 AI 系统的评估提供实践方向。该文件更像是面向第三方评估者的方法论建议,而不是某项新的技术突破或模型成绩报告。它的重点在于如何评估模型能力、模型周边的防护措施,以及一项评估是否真正测量了它声称要测量的内容。换句话说,它把评估质量本身当成了核心问题,而不只是模型表现。
对“可信”的强调反映出,随着前沿系统越来越强大、影响越来越大,外部审视也变得更加重要。这篇内容主要面向那些需要比较、审计或压力测试先进模型的人员,旨在提升行业内的共同做法。根据现有摘要,这份指南传达的核心信息是:对前沿 AI 的评估既需要技术严谨性,也需要对有效性的谨慎把关。OpenAI 将其定位为一个可供生态内其他参与者使用或改编的共享玩法手册。
这份指南讲的是评估方法,而不是新模型发布或新的基准成绩。它强调三个主题:能力评估、防护措施和有效性,说明难点不仅在于衡量性能,还在于确保评估本身可信。
Simon Willison
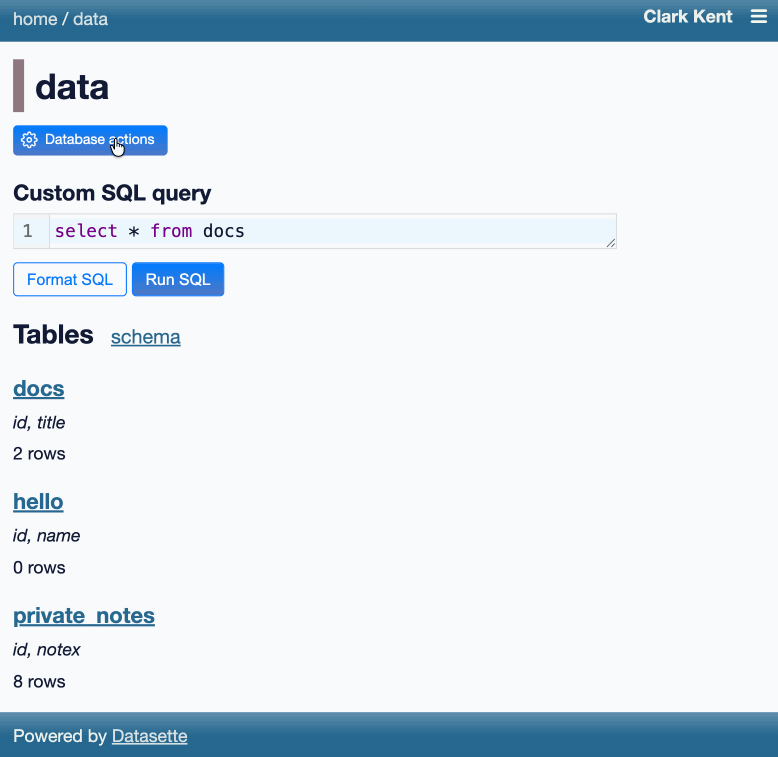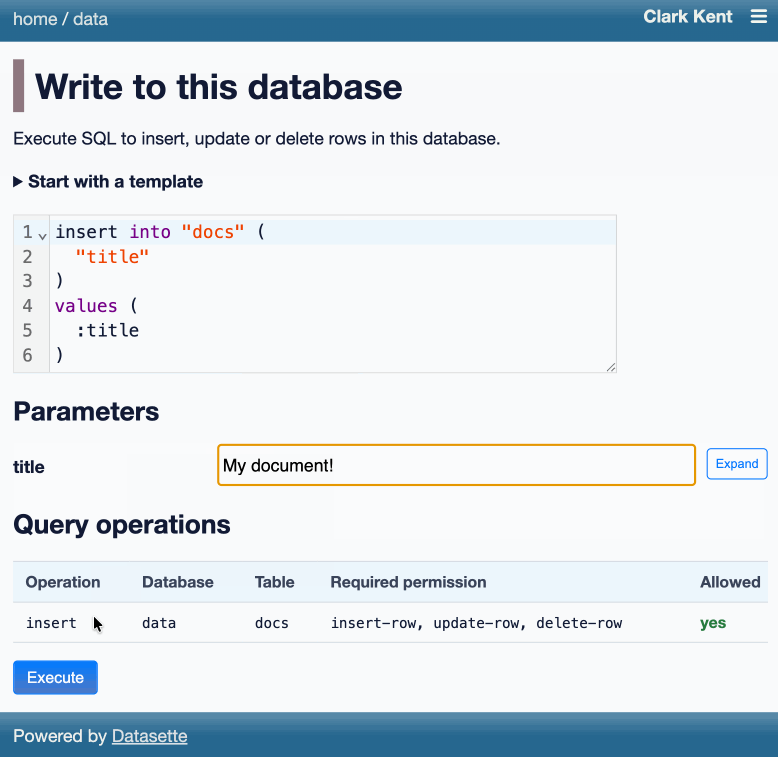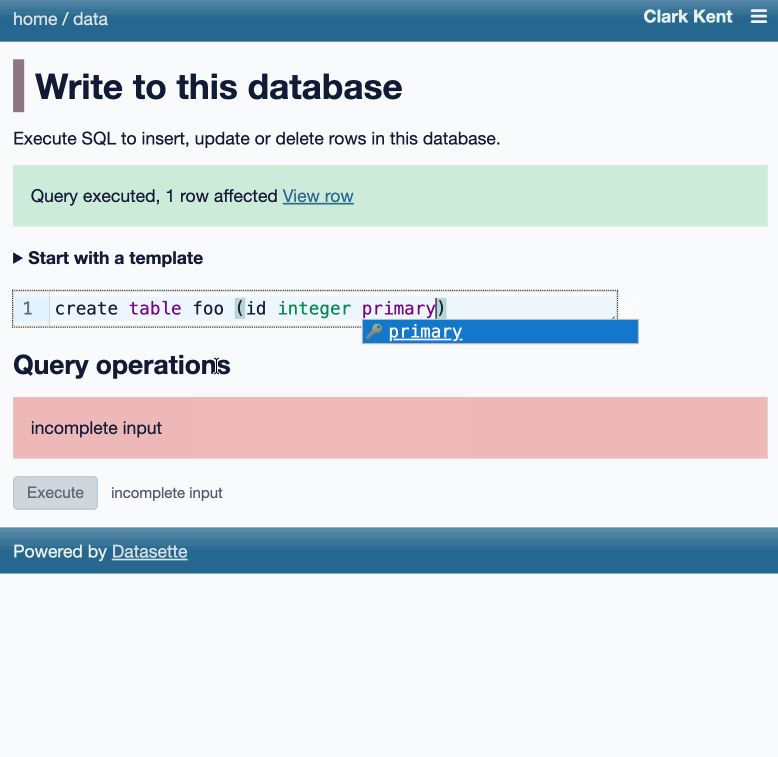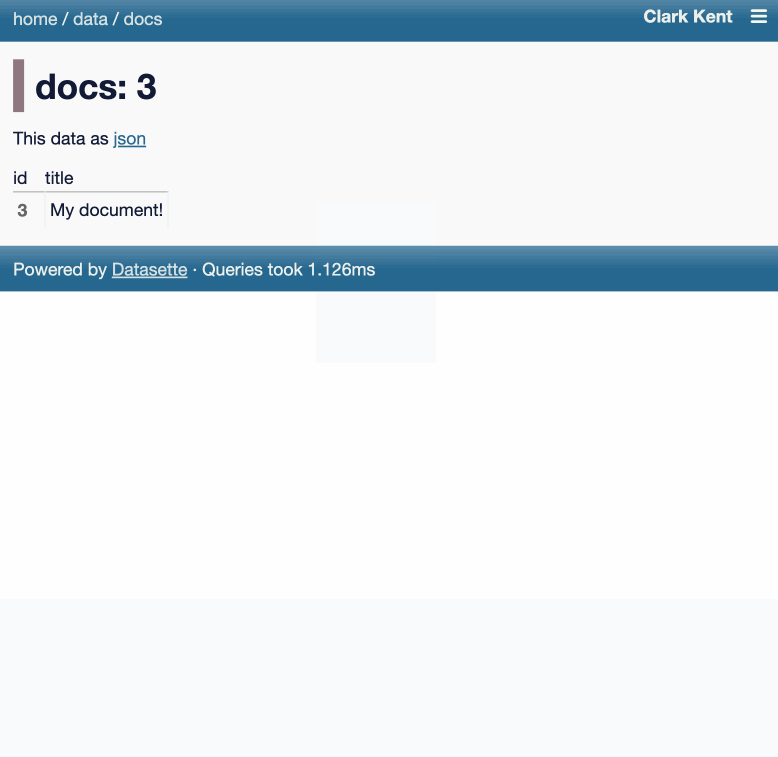
Datasette 1.0a31 是一个新的 alpha 版本,带来了两个重点功能:在权限允许的情况下执行 SQL 写入查询,以及支持保存已存储查询,后者原名为“canned queries”。这些已存储查询现在可以设为私有,或与同一 Datasette 实例中的其他用户共享。
这些变化让 Datasette 不再只是只读浏览工具,而是更接近实用的数据库交互和轻量协作平台。对于希望在共享界面中以受控方式修改数据并重复使用常用查询的团队和高级用户来说,这尤其重要。
Datasette 1.0a31 被描述为又一个重要的 alpha 版本,并带来了两个新的重点功能。发布说明称,拥有必要权限的用户现在可以对数据库执行 SQL 写入查询。它还引入了已保存查询,名称从“canned queries”更改而来,这些查询既可以私有保存,也可以让同一个 Datasette 实例中的其他成员使用。此次发布还链接到一篇更详细的博客文章,专门介绍新的 SQL 写入查询和已保存查询功能。
博客中的动画演示展示了用户从数据库页面开始,打开 actions 菜单并选择“Execute write SQL”。随后,用户可以选择如插入文档之类的模板查询,并用具体值执行,例如文档标题。演示还强调了权限检查:当用户没有相应权限时,CREATE TABLE 语句无法执行。发布说明同时提到,自 Datasette 博客上线两周以来,已经发布了三篇介绍新功能的文章。
写入查询流程受权限控制,演示展示了针对用户有编辑权限的表提供模板化的 insert、update 和 delete 操作。示例还显示,当用户没有 create-table 权限时,CREATE TABLE 语句会被阻止,这说明该功能仍然遵守现有的访问控制。
TechCrunch AI

Glean reported $300 million in annual recurring revenue as it accelerates growth in enterprise AI search while facing competition from major tech companies.
Glean crossing $300M ARR is a notable enterprise AI growth milestone, especially amid rising competition from major tech companies entering AI search; however, this is primarily a business update rather than a technical breakthrough, and no discussion/comments were provided to indicate community debate or validation.
Glean, a company often described as the Google for enterprise, said it has reached $300 million in annual recurring revenue (ARR), a three-fold increase from the $100 million milestone it reached just 15 months ago. While many AI startups are growing at a blistering pace, Glean’s progress is particularly remarkable. After years of essentially being the only player in the category, the seven-year-old startup is accelerating its growth as tech giants enter the enterprise AI search market with rival products.
The Decoder

来自 Meta、斯坦福大学和伊利诺伊大学厄巴纳-香槟分校的研究者发表了一篇综述论文,认为代码是 AI 代理进行推理、行动和协作的核心。论文同时强调了围绕模型的“harness”软件层,它能把无状态模型变成持续运行的代理系统。
这篇论文把 AI 代理重新定义为软件系统,而不只是文本生成器,这会直接影响代理架构、测试和安全设计。如果代码和 harness 才是真正的运行层,那么忽略这些层的评估方法就可能低估可靠性与安全风险。
一篇来自伊利诺伊大学厄巴纳-香槟分校、Meta 和斯坦福大学研究者的新综述论文认为,代码不应只被看作 AI 代理的产出,而应被理解为它们进行思考和行动的媒介。作者认为,自治系统的真正瓶颈不是模型本身,而是包裹在模型外面的软件层,也就是他们所说的 “harness”。这个 harness 包括工具、接口、沙箱执行环境、记忆、权限边界、执行循环和反馈通道等组件,让一个无状态模型能够在长任务中持续运行。作者指出,没有这个层,语言模型仍然只是无状态的;有了它,模型才会变成能够规划、执行、测试并反复修正工作的实用代理。论文把长时间运行的代理系统分为三层:模型本身的能力、模型周围的基础设施,以及代理在运行中动态写出的代码。
作者特别强调,这些自生成的代码包括测试脚本、临时辅助工具、可复用技能和可执行工作流,但这一部分长期以来没有得到足够研究。论文还讨论了代码如何通过 Program-of-Thoughts、Chain of Code 和 Code as Policies 等方法,把模型和环境连接起来。对于多代理系统,代码、测试和执行日志会构成共享工作区,让经理、规划者、程序员、审查者和测试者等不同角色协同完成任务。作者还提到,Claude Code 和 OpenAI 的 Codex 等商业系统已经在实践中采用了类似架构。与此同时,论文警告说,现有软件测试往往不完整,可能掩盖关键风险,因此需要更透明的评估机制。
作者把 harness 描述为包含工具、接口、沙箱执行环境、记忆、权限边界、执行循环和反馈通道等组件。他们还警告说,当前的软件测试往往不完整,可能掩盖重要风险,因此需要更透明的评估机制。
The Verge AI

一家名为 Shift 的AI训练初创公司提出为纽约人的家庭提供免费清洁服务,交换条件是拍摄家务劳动的视频素材。文章还提到,印度的 Pronto 以及像 Human Archive 这样的数据采集初创公司也在开展类似做法。
机器人公司需要大量真实世界数据来训练具身AI系统,而家务劳动正是最难仅靠互联网数据学会的物理任务。这一趋势说明,高质量训练数据已经成为机器人领域的重要竞争优势,也会影响消费者、零工劳动者和开发家用机器人的初创公司。
《The Verge》报道,AI 和机器人公司正越来越愿意为人们做家务时的视频付费,因为这些数据对训练机器人在真实物理世界中工作至关重要。名为 Shift 的AI训练初创公司表示,它将为纽约人的家庭提供免费清洁服务,并计划扩展到包括伦敦在内的其他城市,但作为交换,它希望拍摄清洁工擦洗碗碟、擦台面、掸灰和拖地的工作视频。文章指出,这并不只是为了提供便利服务,而是为了收集机器人学习所必需的真实物理数据。与聊天机器人或图像生成器不同,机器人必须理解空间、运动、力量、摩擦、复杂光照和不规则材料,这使得人类看来很简单的任务,例如叠衣服或倒水,都很难被机器编码和学习。由于物理世界不像文本和图片那样容易从互联网上大规模抓取,高质量数据已成为具身AI的主要瓶颈。文章还提到其他类似做法:在印度,Pronto 被报道把客户家中作为家务AI训练素材来源,尽管它声称只有在客户明确同意后才会录制。
该做法引发了市场强烈反弹,竞争对手也纷纷表示自己从未在住户家中录制训练AI的视频,也无此计划。其他公司,如位于硅谷的 Human Archive,则试图通过让零工劳动者佩戴带摄像头的帽子来规模化采集数据。与此同时,Shift 还声称已在 15 个国家向数万人支付报酬,让他们通过应用程序记录自己的活动。文章还描述了“数据农场”这种做法,即让工人一遍又一遍重复同样的体力动作,由摄像头和传感器完整记录,用来生成训练素材。最后,文章指出,一些数据甚至会来自已经在用户家中运行的机器人本身,当机器人卡住时,远程工作人员会介入,而这些救援过程也会继续产生可用于训练的数据。
文章强调,机器人必须处理运动、力量、摩擦、奇怪的形状、材料和光照条件,因此家务劳动远比文本类AI任务更难自动化。有些公司通过可穿戴摄像设备采集第一人称视角数据,另一些则让人反复执行同样的体力任务来搭建“数据农场”,还有公司直接使用已经部署到客户家中的机器人所产生的素材。
ZDNET AI

IBM和Red Hat正在支持Project Lightwell,这是一个新的AI驱动开源安全计划,计划在未来几年投入50亿美元。两家公司还表示,将投入2万名工程师来识别、分类并帮助修复关键开源软件中的漏洞。
开源软件支撑着现代企业基础设施的大部分,因此更快地处理漏洞有望在大规模上降低供应链风险。这个计划也反映出行业正在回应维护者倦怠,以及单个项目难以处理的海量安全报告问题。
ZDNET报道,IBM和Red Hat正在推出Project Lightwell,这是一个旨在以工业规模修复开源安全问题的AI驱动计划。该计划被描述为对维护者压力不断上升的回应,因为他们正被海量安全报告淹没,难以跟上处理速度。文章引用了cURL维护者Daniel Steinberg的话,他表示现在收到的安全报告数量比2024年高出4到5倍,他自己也已经接近倦怠。IBM和Red Hat的回应并不是传统的漏洞赏金项目或扫描工具,而是一种新的运营模式,充当企业与上游社区之间可信的中介。
企业会提供他们所依赖的开源软件信息,而Lightwell工程师将利用AI查找漏洞、对结果进行优先级排序,并提出修复方案。随后,这些工程师会与上游维护者合作,让补丁被合并并发布,同时该服务还计划支持回移植和长期生命周期维护,以覆盖企业实际部署的版本。两家公司表示,他们将在未来几年投资50亿美元,并投入2万名工程师,把开源风险当作供应链层面的关键问题,而不是次要维护任务。IBM首席执行官Arvind Krishna表示,该项目旨在定义一种新的行业模式,把AI、工程专业能力和可信协作结合起来,从源头到整个供应链来保护开源软件。
Lightwell被描述为一种“清算中心”模式:企业提供其使用的开源组件信息,然后IBM和Red Hat工程师利用AI查找漏洞、提出修复方案,并与上游维护者合作合并补丁。文章还提到,这项服务不会直接向上游开发者付费,而且这种订阅式模式的一些运营细节仍不清楚。
Ars Technica AI

德国初创公司 MicroAGI 推出了 Shift,这是一项面向纽约市的清洁服务:用户如果同意让佩戴摄像设备的清洁人员记录工作过程,就可以获得免费家政清洁。录制的视频将用于训练家用机器人相关的 AI 系统。
这一模式把日常家务变成了第一视角机器人训练数据的来源,而这类数据对需要真实世界样本的具身 AI 很有价值。如果可行,它可能降低数据采集成本,并加速能够处理复杂家庭环境的机器人研发。
德国初创公司 MicroAGI 正在推广一项名为 Shift 的新服务,面向纽约市居民提供免费上门清洁。作为交换,用户需要同意让专业清洁人员佩戴带摄像头的设备,在擦洗、吸尘、除尘、整理和洗涤等过程中记录第一视角视频。公司声称,这些数据的价值足以覆盖清洁成本,因此才会提供“免费清洁”服务。Shift 在 5 月 28 日通过 X 和 LinkedIn 对外公布了这一计划,并配了一段宣传视频,背景音乐选用了《Empire State of Mind》。公司联合 CEO 兼联合创始人 Bercan Kilic 解释说,视频里那顶被称为“magic hat”的帽子内置摄像头,用来拍摄清洁人员的视角。
Shift 表示,这些素材将用于训练下一代家用机器人,而且环境越复杂、越“难清理”,往往越有助于生成有价值的数据。公司还称,清洁人员由合作伙伴审查,但并不是 Shift 的员工,并且他们可以拒绝自己不愿执行的具体任务。关于隐私,Shift 说姓名、人脸以及来自屏幕、身份证件和纸张等内容的敏感信息都会在用于 AI 训练前被模糊和匿名化。其隐私政策进一步说明,这些处理会先在智能眼镜或视频采集设备上完成,然后再上传到云端。不过,报道也指出,仍不清楚用户是否能要求自己的清洁视频从训练数据集中删除,以及这些匿名化手段是否足以防止房屋身份被推断出来。
Shift 表示,它会在智能眼镜或视频采集设备上直接运行机器学习模型,在上传云端之前自动模糊人脸、身份证件、屏幕和其他识别信息。不过,公司尚未明确说明房主是否可以事后要求将自己的视频从训练数据集中删除,其匿名化措施是否足够可靠也仍不清楚。
Financial Times AI
新任财政部首席秘书露西·里格比表示,如果公共服务不使用AI,就等于“选择衰退”。这一表态意味着英国政府正推动在Whitehall范围内扩大技术应用。
这一表态反映出英国政府希望通过数字工具来现代化公共服务并提升国家治理能力。如果AI被广泛采用,它可能会影响公务员在行政管理、公共服务交付和各部门生产力方面的工作方式。
《金融时报》报道称,新任财政部首席秘书露西·里格比希望在Whitehall范围内推广技术。她的观点被概括为:如果公共服务不使用AI,就等于“选择衰退”。报道将她的表态放在英国政府更广泛的数字化转型背景下进行解读。Whitehall是英国中央政府的核心,因此这番话意味着相关推动可能会覆盖中央各部委和公共行政体系。
尽管现有内容很简短,但核心信息很明确:这位财政部部长正在把AI视为国家现代化议程的一部分。这样的表述意味着AI不再只是可选的试验项目,而是维持公共服务效率和竞争力所必需的工具。根据所给材料,没有提到具体的AI系统、试点项目或实施时间表。
文章指出,露西·里格比是新任财政部首席秘书,并将她的立场描述为支持在Whitehall全面推广技术。在英国语境中,Whitehall通常指中央政府及其各部委,因此这项政策关注的是广泛部署,而不是某一个单独部门。
Hugging Face Blog

Hugging Face 发布了“Profiling in PyTorch”系列的第一篇,重点介绍 torch.profiler。文章通过一个简单的矩阵乘法加偏置示例,带新手学习如何阅读性能分析轨迹。
性能分析是提升训练和推理速度的关键步骤,尤其是在 LLM 这类工作负载中,细小的低效都会迅速累积。这个系列降低了 PyTorch 用户发现瓶颈的门槛,也为后续使用 torch.compile 等优化手段做准备。
Hugging Face 这篇文章开启了一个关于 PyTorch 性能分析的系列,而且明确面向初学者。文章的核心观点是:如果不能进行性能分析,就无法进行优化,因此 profiling 对提升每秒 token 数、降低推理延迟、以及解释训练循环为什么比预期更慢都非常重要。作者也承认,profiler trace 往往很吓人,因为里面充满了密集的彩色块和陌生的事件名称,所以这个系列的目标就是降低阅读门槛。第一部分选择了最简单的例子:矩阵乘法后接一个偏置加法。示例脚本名为 01_matmul_add.py,并在 NVIDIA A100-SXM4-80GB GPU 上运行,文章还建议在正式采集前多运行几次以完成 GPU 预热。
文中展示了如何使用 torch.profiler.record_function 给代码打标签,以及如何用开启 CPU 和 CUDA 活动的 torch.profiler.profile 上下文管理器包住要分析的代码。随后,读者会被引导去查看 profiler 表格和 trace 视图,并注意 CPU 轨道、GPU 轨道以及它们之间的空隙。文章还先解释了两个基础概念:GPU kernel 是在 GPU 上并行运行的程序,而 CPU 负责调度和启动这些 kernel。系列后续内容会逐步扩展到 nn.Linear 和小型 MLP,最后再延伸到使用 transformers 的大型语言模型,并借助 trace 来解释优化以及 torch.compile 带来的变化。
文章使用了一个最小脚本 01_matmul_add.py,并在 NVIDIA A100-SXM4-80GB GPU 上运行,展示了如何用 torch.profiler.record_function 和 torch.profiler.profile 包装代码。文章还说明,用户需要同时查看 profiler 表格和 Chrome trace,包括 CPU 轨道、GPU 轨道以及它们之间的空隙,才能理解在应用 torch.compile 后哪些部分发生了变化、哪些没有变化。
Simon Willison
llm-anthropic 0.25.1 新增了对 Claude Opus 4.8 的支持,对应模型名为 `claude-opus-4.8`。它还为已开通该功能的组织加入了 `-o fast 1` 快速模式选项,并把默认 `max_tokens` 改为使用每个模型的最大输出上限,而不再固定为 8192。
这些更新让使用 Anthropic 模型的开发者能更直接地受益,尤其是想使用最新 Claude 版本或更高吞吐量快速模式的人。新的默认 token 行为也降低了配置成本,并有助于避免不必要地限制模型输出长度。
2026 年 5 月 28 日,Simon Willison 发布了 llm-anthropic 0.25.1,这是他为 `llm` 工具生态提供的 Anthropic 集成的一个常规但实用的更新。此次发布新增了对 Claude Opus 4.8 的支持,对应模型名为 `claude-opus-4.8`,因此用户可以在工作流中直接选择这个新模型。它还加入了新的 `-o fast 1` 快速模式选项,但前提是组织账户已经开通了该功能。
另一个重要变化是默认 `max_tokens` 的行为:库不再固定使用 8192,而是默认采用每个模型自身的最大输出上限。Willison 还提到,他就是用这个新版 llm-anthropic 生成了他在 Opus 4.8 相关笔记里提到的那些鹈鹕内容。整篇文章更像是一则简短的发布说明,而不是深入的技术分析,且给定内容中没有包含讨论区或用户评论。
这次发布明确说明,`max_tokens` 现在会默认采用各模型自己的最大输出上限,而不是统一的 8192 token 上限。快速模式选项只对账户中已启用该功能的组织可用,因此并不是所有用户都能使用的通用设置。
TechCrunch AI

Cognition 首席执行官 Scott Wu 告诉 TechCrunch,公司的 AI 编码代理 Devin 并不是用来取代程序员的,尽管 Cognition 刚刚以 260 亿美元估值融资 10 亿美元。他表示,Devin 的设计目标是帮助开发者端到端完成工作并承担繁琐任务,而不是让人类程序员失业。
这番表态出现在许多科技公司把 AI 描述为劳动力替代品的背景下,尤其是在软件工程领域。Wu 的观点代表了一种不同的路线:编码代理不是消灭开发者,而是扩展开发者的能力。
Cognition 首席执行官 Scott Wu 在接受 TechCrunch 采访时谈到了公司刚完成的一轮融资:这家成立两年的 AI 编码代理初创公司融资 10 亿美元,估值达到 260 亿美元。Cognition 是 Devin 的开发者,Wu 称它是最早、也可以说最成功的 AI 编码代理之一,公司还曾在公告中描绘“自驱动软件开发”的愿景。尽管如此,Wu 仍然反对把 Devin 理解为要取代人类程序员。 他表示,公司从未把产品定位成替代人类,即使它在某些任务上确实可以独立工作。Wu 强调,自己和团队本身就是程序员,并且希望 AI 工具能保留编程的乐趣。 他把编码代理类比为另一层抽象,就像可视化开发环境曾把软件创建从机器指令中抽离出来一样。
Cognition 还称,Devin 已经在公司内部承担了几乎所有软件交付工作;公司声称,工程师提交的代码中有 89% 由 Devin 完成,其余来自去年收购的竞争对手 Windsurf 的本地代理。Wu 说,Devin 最适合处理那些很多程序员并不喜欢做的长尾维护任务,例如让旧软件升级到新版本、把应用从一个平台迁移到另一个平台。 在他看来,这样的系统能把工程师从大量琐碎工作中解放出来,让他们把更多时间花在创造性工作上。 他还表示,Devin 在不同任务上的能力大致介于初级和中级工程师之间。 展望未来,Wu 认为 AI 代理会进入客户服务、医疗等更多行业,但他希望这些领域同样应以“人类决定做什么”为原则。
Wu 表示,Devin 目前在不同任务上的表现大致介于初级和中级工程师之间,而 Cognition 还称其工程师提交的代码中有 89% 由 Devin 完成。他补充说,这类系统尤其适合处理长尾维护工作,例如升级旧软件和把应用迁移到不同平台。
The Decoder

Axios报道称,一家未具名公司据称因没有为Claude许可证设置使用上限,在一个月内花了5亿美元。文章把这件事描述为企业AI成本失控的极端案例,反映出当缺乏配额和治理时,支出可能迅速失控。
这则故事凸显了企业正在面对的一个新问题:AI落地不再只是接入模型,更重要的是控制开支、选择合适的模型并证明投资回报。对于CTO、财务团队和AI平台主管来说,这意味着必须像管理其他关键生产资源一样管理AI使用。
文章开头指出,AI正在变得越来越贵,企业也开始更仔细地审视自己的AI账单。文中提到,微软据称已经削减了内部的Claude Code许可,原因既包括战略考量,也包括成本持续上升;Uber的COO则表示,在难以衡量实际投资回报时,AI支出会变得“更难证明合理”。随后,Axios报道了一个更夸张的案例:一家未具名公司据称因为没人给Claude许可证设置使用上限,在一个月内花掉了5亿美元。文章指出,企业AI定价看起来像是固定月费,但这类套餐通常仍会对每个模型的请求次数设限。
文章还引用了前微软AI负责人Sophia Velastegui的观点:很多公司把AI用在“没人想做的任务”上,而不是用在真正能创造收入的工作上。作者认为,企业需要更多懂得控制和调度AI系统的内部人才,包括新的“AI agent orchestrators”等岗位。文章最后强调,最大的成本问题来自误用和模型选择不当,而且并不是每项任务都需要生成式AI,因为很多工作仍然更适合传统软件来处理。
报道指出,企业AI套餐虽然看起来像按月固定收费,但通常仍会设置请求上限,超出后成本可能非常高。文章还认为,误用、模型选择不当以及过大的上下文窗口是主要成本来源,而许多任务其实可以用更便宜的工具,甚至传统软件来完成。
The Decoder

据报道,亚马逊已经关闭了内部 AI 排名面板“Kirorank”,因为员工通过把 AI 用在无意义的任务上来刷分。公司表示,这套系统本意良好,但最终却鼓励了额外的云成本和没有价值的使用行为。
这个案例说明,如果生产力指标奖励的是“使用量”而不是“有效产出”,指标就很容易被刷分,这对大规模推广 AI 工具的企业都具有警示意义。它也凸显了推动 AI 普及与控制基础设施支出之间的矛盾。
据《金融时报》报道,亚马逊已经移除了一个内部 AI 排名系统,因为员工把它“刷”坏了。这个系统名为 Kirorank,依据员工在公司 Kiro 开发平台上的活动来打分。结果并没有促进更高效的 AI 使用,反而让一些员工把 AI 代理用在琐碎、无意义的任务上,只为了在排行榜上提高名次。高级副总裁 Dave Treadwell 据称对员工表示:“请不要只为了使用 AI 而使用 AI。
”他还承认,这个面板虽然出发点是好的,但最终带来了额外的云成本。这个时间点对亚马逊来说比较尴尬,因为公司此前设定了一个目标:让超过 80% 的开发者每周都使用 AI,并计划在 2026 年支出约 2000 亿美元,其中大部分用于 AI 基础设施。据称,类似的指标追逐现象也出现在 Meta。亚马逊现在不再看原始 token 消耗,而是改为衡量“normalized deployments”,也就是那些真正有用的 AI 生成代码。
该面板跟踪的是亚马逊 Kiro 开发平台上的活动,据报道,一些员工会把 AI 代理指向琐碎任务,只为了提升排名。亚马逊随后改为衡量“normalized deployments”,也就是 AI 生成且真正有用的代码,而不是原始 token 消耗量。