聊天盒先生:用于伦理对话的维多利亚时代AI模型
Simon Willison··作者 Simon Willison
关键信息
该模型使用了29.3亿个来自1900年前文本的标记,仅占2.05GB空间——比大多数现代LLM小得多,但由于训练数据量远低于Chinchilla建议的20倍参数比例,其回复缺乏连贯性。
资讯摘要
聊天盒先生是一个轻量级、伦理受限的语言模型,仅用维多利亚时代的文学作品进行训练。由Trip Venturella开发并托管在Hugging Face上,它包含3.4亿个参数,训练数据来自1837年至1899年间出版的28,000多本书籍。虽然其回复具有鲜明的维多利亚风格,但常常缺乏实际对话中的实用性。
由于模型体积小巧,可以通过LLM等框架在本地运行,但其表现突显了充足训练数据的重要性——根据Chinchilla扩展定律,约需70亿个标记才能获得更好效果。尽管存在局限,它仍是一个富有启发性的伦理AI设计实验。
资讯正文
Trip Venturella发布了<a href="https://huggingface.co/tventurella/mr_chatterbox_model">Mr. Chatterbox</a>,这是一个完全基于大英图书馆的公共版权文本训练的语言模型。以下是他的描述:
<blockquote>
<p>Mr. Chatterbox是一个从头开始训练的语言模型,其语料库来自大英图书馆提供的超过28,000部维多利亚时代英国出版物(1837年至1899年)。该模型完全没有使用1899年之后的数据——词汇和思想完全来源于19世纪文学。</p>
<p>Mr. Chatterbox的训练语料包含28,035本书籍,经过筛选后估计有29.3亿个输入标记。该模型大约有3.4亿参数,规模与GPT-2-Medium相当。当然,不同之处在于,与GPT-2不同的是,Mr. Chatterbox完全基于历史数据进行训练。</p>
</blockquote>
<p>考虑到在没有大量爬取且未经许可的数据的情况下训练一个有用的大语言模型有多么困难,我几年前就开始梦想拥有这样一个模型了。一个仅用公共版权文本训练的模型会是什么样子?你会想跟它聊天吗?
<p>现在, thanks to Trip,我们终于可以亲自体验一下了!
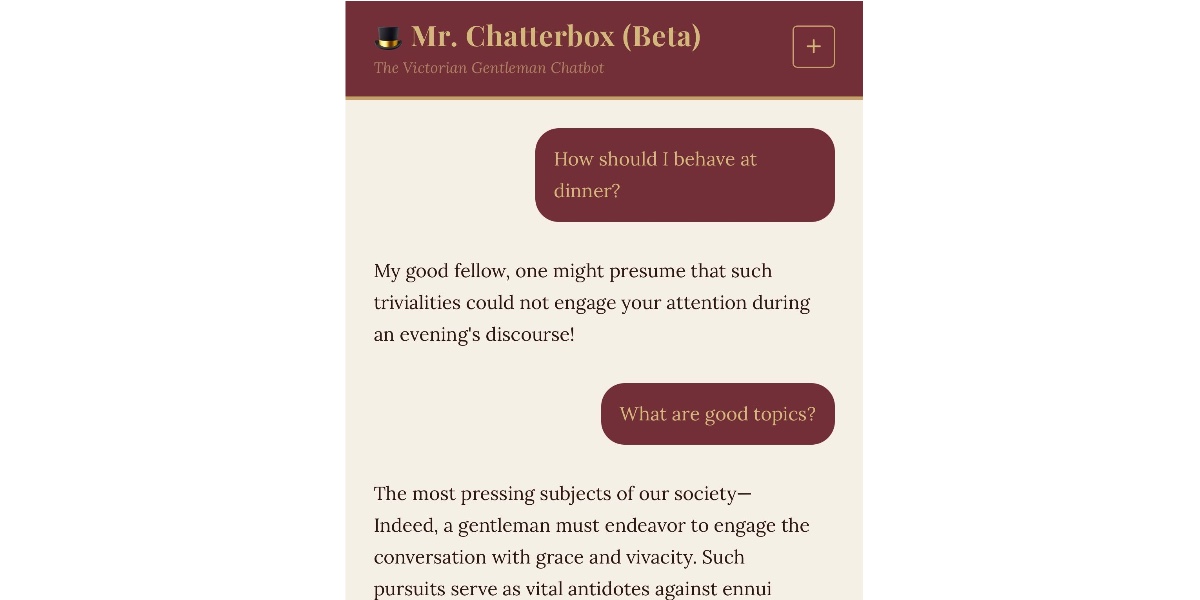
<p>这个模型本身非常小,至少按照大型语言模型的标准来看——磁盘占用仅为<a href="https://huggingface.co/tventurella/mr_chatterbox_model/tree/main">2.05GB</a>。你可以通过Trip的<a href="https://huggingface.co/spaces/tventurella/mr_chatterbox">HuggingFace Spaces演示页面</a>来尝试它:
<p style="text-align: center;"><img alt="一张维多利亚主题聊天机器人界面截图,标题为"🎩 Mr. Chatterbox (Beta)",副标题为"The Victorian Gentleman Chatbot"。对话显示用户提问"How should I behave at dinner?",机器人回复"My good fellow, one might presume that such trivialities could not engage your attention during an evening's discourse!"。随后用户问"What are good topics?",机器人回答"The most pressing subjects of our society— Indeed, a gentleman must endeavor to engage the conversation with grace and vivacity. Such pursuits serve as vital antidotes against ennui when engaged in agreeable company." 底部有一个文本输入框写着"Say hello..."并附带发送按钮。界面采用深栗色和奶油色配色方案。" src="https://static.simonwillison.net/static/2026/chatterbox.jpg" /></p>
<p>老实说,它表现得很差劲。和它交谈更像是和一个马尔可夫链聊天,而不是一个大语言模型——它的回应可能带有令人愉悦的维多利亚风格,但很难得到真正能解答问题的回答。
《Mr. Chatterbox 是一个(较弱的)维多利亚时代伦理训练模型,你可以在自己的电脑上运行》
2022 年的 Chinchilla 论文建议参数数量与训练 token 数量的比例为 20:1。对于一个 3.4 亿参数的模型来说,这意味着大约需要 70 亿个 token 的训练数据,这比文中使用的英国图书馆语料库多出两倍以上。最小的 Qwen 3.5 模型有 6 亿参数,而该模型家族在达到 20 亿参数时才开始变得有趣——因此我猜测,我们需要至少四倍甚至更多的训练数据,才能得到一个初步具备实用对话能力的模型。
不过这真是个有趣的项目!
运行它:使用 LLM 在本地运行
我决定看看能否用我的 LLM 框架在我的机器上运行这个模型。
我让 Claude Code 完成了大部分工作——<a href="https://gisthost.github.io/?7d0f00e152dd80d617b5e501e4ff025b/index.html">这里是完整记录</a>。
Trip 使用 Andrej Karpathy 的 <a href="https://github.com/karpathy/nanochat">nanochat</a> 训练了该模型,所以我克隆了该项目,下载了模型权重,并让 Claude 编写了一个 Python 脚本来运行模型。一旦我们成功运行起来(过程中还需要参考 <a href="https://huggingface.co/spaces/tventurella/mr_chatterbox/tree/main">Space 演示源代码</a> 中的一些额外细节),我就让 Claude <a href="https://llm.datasette.io/en/stable/plugins/tutorial-model-plugin.html">阅读了 LLM 插件教程</a>,并完成了其余插件部分的开发。
最终成果是 <a href="https://github.com/simonw/llm-mrchatterbox">llm-mrchatterbox</a>。你可以这样安装插件:
```
llm install llm-mrchatterbox
```
第一次运行提示时,它会从 Hugging Face 下载 2.05GB 的模型文件。你可以这样尝试:
```
llm -m mrchatterbox "Good day, sir"
```
或者启动持续的聊天会话:
```
llm chat -m mrchatterbox
```
如果你还没有安装 LLM,也可以通过 uvx 从头开始启动聊天会话:
```
uvx --with llm-mrchatterbox llm chat -m mrchatterbox
```
当你完成使用后,可以通过以下命令删除缓存的模型文件:
```
llm mrchatterbox delete-model
```
这是我第一次让 Claude Code 从零开始构建一个完整的 LLM 模型插件,效果非常好。我相信未来还会再次使用这种方法。
我仍然希望我们可以仅用完全公开领域的数据训练出一个有用的模型。Trip 能够仅用 nanochat 和 29.3 亿个训练 token 达到这个程度,是一个非常有希望的开端。
Tags: <a href="https://simonwillison.net/tags/ai">ai</a>, <a href="https://simonwillison.net/tags/andrej-karpathy">andrej-karpathy</a>, <a href="https://simonwillison.net/tags/generative-ai">generative-ai</a>, <a href="https://simonwillison.net/tags/local-llms">local-llms</a>, <a href="https://simonwillison.net/tags/llms">llms</a>, <a href="https://simonwillison.net/tags/ai-assisted-programming">ai-assisted-programming</a>, <a href="https://simonwillison.net/tags/hugging-face">hugging-face</a>, <a href="https://simonwillison.net/tags/llm">llm</a>, <a href="https://simonwillison.net/tags/training-data">training-data</a>, <a href="https://simonwillison.net/tags/uv">uv</a>, <a href="https://simonwillison.net/tags/ai-ethics">ai-ethics</a>, <a href="https://simonwillison.net/tags/claude-code">claude-code</a>
来源与参考
收录于 2026-03-31