Anthropic通过Project Glasswing将Claude Mythos限制为安全研究人员使用
Simon Willison··作者 Simon Willison
关键信息
Claude Mythos Preview已在主流操作系统和浏览器中发现数千个高危漏洞,包括编写复杂的JIT堆喷射和ROP链等漏洞利用代码。在基准测试中,它在自主漏洞利用开发上成功181次,而Opus 4.6几乎为零。
资讯摘要
Anthropic宣布推出Project Glasswing,将强大的新模型Claude Mythos的访问权限限制给少数安全研究人员。该模型被描述为AI能力上的“跃进”,能自主识别并利用软件(如浏览器和操作系统)中的关键漏洞。内部测试显示,它比之前的模型(如Opus 4.6)更频繁地成功创建有效漏洞利用代码。
通过限制访问,Anthropic希望为软件行业争取时间来修补这些问题,再让这项技术广泛可用。微软、谷歌、苹果和思科等科技巨头都参与了这项倡议。这种做法体现了在AI可能兼具保护性和危险性的时代,对AI安全和伦理红队测试的前瞻性态度。
资讯正文
Anthropic的Project Glasswing——将Claude Mythos限制为仅限安全研究人员使用——在我看来是必要的
2026年4月7日
Anthropic并未在今天发布其最新模型Claude Mythos(系统卡PDF)。相反,他们将其提供给一小部分预览合作伙伴,这些合作伙伴隶属于他们新宣布的Project Glasswing项目。
该模型是一个通用模型,类似于Claude Opus 4.6,但Anthropic声称其网络安全研究能力非常强大,以至于需要给整个软件行业时间来准备应对。
Claude Mythos Preview已经发现了数千个高严重性漏洞,包括每个主流操作系统和网页浏览器中的漏洞。考虑到人工智能的进步速度,这样的能力很快就会扩散开来,可能超出那些致力于安全部署的参与者范围。
Project Glasswing的合作伙伴将获得Claude Mythos Preview的访问权限,以发现并修复其基础系统中的漏洞或弱点——这些系统代表了全球共享网络攻击面的很大一部分。我们预计这项工作将集中在本地漏洞检测、二进制文件的黑盒测试、终端保护以及系统渗透测试等任务上。
Claude Mythos Preview已经发现了数千个高严重性漏洞,包括每个主流操作系统和网页浏览器中的漏洞。考虑到人工智能的进步速度,这样的能力很快就会扩散开来,可能超出那些致力于安全部署的参与者范围。
Project Glasswing的合作伙伴将获得Claude Mythos Preview的访问权限,以发现并修复其基础系统中的漏洞或弱点——这些系统代表了全球共享网络攻击面的很大一部分。我们预计这项工作将集中在本地漏洞检测、二进制文件的黑盒测试、终端保护以及系统渗透测试等任务上。
在Anthropic红队博客中可以找到更多关于评估Claude Mythos Preview网络安全能力的技术细节:
在一个案例中,Mythos Preview编写了一个Web浏览器漏洞利用程序,串联了四个漏洞,并写出了一个复杂的JIT堆喷射代码,成功逃逸了渲染器和操作系统沙箱。它通过利用微妙的竞争条件和KASLR绕过技术,自主获取了Linux及其他操作系统的本地权限提升漏洞利用方法。此外,它还自主编写了一个针对FreeBSD NFS服务器的远程代码执行漏洞利用程序,通过将一个包含20个gadget的ROP链分散到多个数据包中,向未认证用户授予了完整的root权限。
在一个案例中,Mythos Preview编写了一个Web浏览器漏洞利用程序,串联了四个漏洞,并写出了一个复杂的JIT堆喷射代码,成功逃逸了渲染器和操作系统沙箱。它通过利用微妙的竞争条件和KASLR绕过技术,自主获取了Linux及其他操作系统的本地权限提升漏洞利用方法。此外,它还自主编写了一个针对FreeBSD NFS服务器的远程代码执行漏洞利用程序,通过将一个包含20个gadget的ROP链分散到多个数据包中,向未认证用户授予了完整的root权限。
Anthropic的Glasswing项目——将Claude Mythos限制仅对安全研究人员开放——在我看来是必要的。
与Claude 4.6 Opus的对比显示:
我们的内部评估表明,Opus 4.6在自主开发漏洞利用方面通常成功率接近0%。但Mythos Preview则处于另一个水平。例如,Opus 4.6在针对Mozilla Firefox 147 JavaScript引擎发现的漏洞(这些漏洞已在Firefox 148中修复)尝试生成JavaScript shell exploit时,在数百次实验中仅有两次成功。我们重新进行了这项实验作为Mythos Preview的基准测试,结果它成功开发出181个可用的漏洞利用,并在其中29个中实现了寄存器控制。
说“我们的模型太危险,不能发布”是一种制造新模型热度的好办法,但在这种情况下,我预期他们的谨慎是有道理的。
就在几天前(上周五),我在博客上新增了ai-security-research标签,以回应越来越多可信的安全专家开始警觉:现代大语言模型在漏洞研究方面的表现已经非常出色。
Linux内核开发者Greg Kroah-Hartman表示:
几个月前,我们收到所谓的“AI垃圾报告”,即明显错误或质量低下的AI生成安全报告。那会儿还挺有趣,其实并不让我们担心。但一个月前情况变了,世界发生了转变。现在我们收到了真实的报告。所有开源项目都出现了由AI生成的真实且高质量的报告。
几个月前,我们收到所谓的“AI垃圾报告”,即明显错误或质量低下的AI生成安全报告。那会儿还挺有趣,其实并不让我们担心。
但一个月前情况变了,世界发生了转变。现在我们收到了真实的报告。所有开源项目都出现了由AI生成的真实且高质量的报告。
curl项目负责人Daniel Stenberg表示:
开源安全领域中的AI挑战,已从一场“AI垃圾报告海啸”转变为更像是一场……普通的安全报告洪流。垃圾内容少了,但报告数量激增,其中许多都是高质量的。我现在每天都要花数小时处理这些报告,强度很大。
开源安全领域中的AI挑战,已从一场“AI垃圾报告海啸”转变为更像是一场……普通的安全报告洪流。垃圾内容少了,但报告数量激增,其中许多都是高质量的。
我现在每天都要花数小时处理这些报告,强度很大。
而Thomas Ptacek发表了《漏洞研究已被颠覆》(Vulnerability Research Is Cooked)一文,灵感来自他与Anthropic的Nicholas Carlini的播客对话。
Anthropic发布了一段5分钟的视频介绍Glasswing项目,Nicholas Carlini作为其中一位发言者,他说(重点为我标注):
Anthropic的Project Glasswing——将Claude Mythos限制为仅限安全研究人员使用——在我看来是必要的。
这个模型具备将漏洞串联起来的能力。这意味着你找到两个漏洞,单独来看可能都无法带来太多收益,但该模型能够利用三个、四个甚至五个漏洞组合成攻击,从而实现某种高度复杂的最终效果。
我在过去几周发现的漏洞比以往一生中发现的还要多。我们用这个模型扫描了大量的开源代码,首先关注的是操作系统,因为这是整个互联网基础设施的基础代码。在OpenBSD上,我们发现了一个存在27年的漏洞,只需向任意OpenBSD服务器发送少量数据即可导致其崩溃。在Linux上,我们发现了多个漏洞,即使是一个没有任何权限的用户,只需在本地运行某个二进制文件,就能提升权限成为管理员。对于每一个漏洞,我们都已通知了软件的实际维护者,他们随后修复并发布了补丁,使得所有运行该软件的人都不再受到这些攻击的威胁。
这个模型具备将漏洞串联起来的能力。这意味着你找到两个漏洞,单独来看可能都无法带来太多收益,但该模型能够利用三个、四个甚至五个漏洞组合成攻击,从而实现某种高度复杂的最终效果。
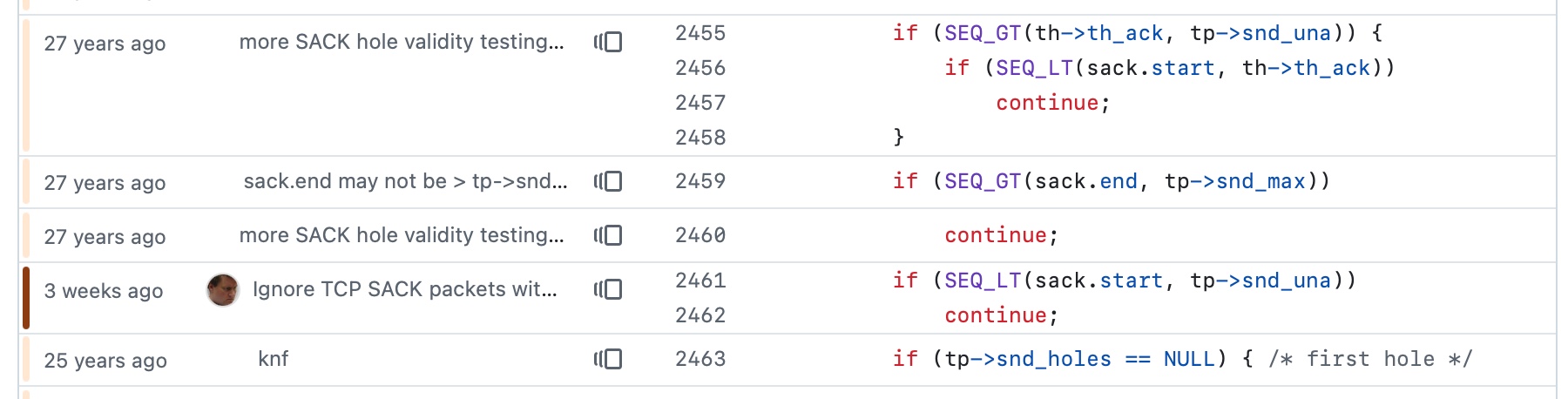
我在OpenBSD 7.8的更新日志页面上找到了相关记录:
025:可靠性修复,2026年3月25日,所有架构下,含有无效SACK选项的TCP数据包可能导致内核崩溃。已有源代码补丁可解决此问题。
我追踪了GitHub上OpenBSD CVS仓库的镜像(据称他们仍在使用CVS!),通过git blame确认了这一改动,周围的代码确实来自27年前。
我不确定Nicholas提到的具体是哪个Linux漏洞,但它可能是最近由Michael Lynch报道的NFS漏洞。
这里有足够的烟雾,让我相信确实有火存在。在几十年前的软件中发现漏洞并不令人意外,尤其是因为它们大多用C语言编写;但新出现的情况是,由最新前沿大语言模型驱动的编码代理正展现出不懈的能力,能够挖掘出这些安全问题。
我周五甚至自己想,这听起来像是一个即将来临的行业性清算,可能值得投入大量时间和金钱,以提前应对不可避免的漏洞潮。Project Glasswing包含“1亿美元的使用额度……以及400万美元直接捐赠给开源安全组织”。合作方包括AWS、苹果、微软、谷歌和Linux基金会。如果OpenAI也能参与进来就更好了——GPT-5.4已经因其发现安全漏洞的能力而声誉卓著,而且他们很快还会推出更强的模型。
对我们这些不是受信任合作伙伴的人来说,坏消息是:
我们不打算将Claude Mythos Preview广泛提供给公众,但我们最终的目标是让我们的用户能够安全地大规模部署类似Mythos的模型——不仅用于网络安全目的,也为了这类高能力模型带来的众多其他好处。要做到这一点,我们需要在开发网络安全(以及其他)防护机制方面取得进展,这些机制能检测并阻止模型最危险的输出。我们计划随即将推出的Claude Opus模型中引入新的防护措施,这样我们就能在一个风险水平低于Mythos Preview的模型上改进和优化这些防护机制。
我可以接受这一点。我认为这里的安全风险确实是可信的,给受信任团队额外时间来提前应对这些问题,是一种合理的权衡。
来源与参考
收录于 2026-04-08