Cloudflare 把 AI 代理的部署流程降到“临时账户”级别
临时账户和 `wrangler deploy --temporary` 让代理可立即上线并在 60 分钟内被认领,直接减少注册、令牌和 MFA 对自动化工作流的阻塞。
AI 日报
今天的核心主题是:AI 正从“能回答问题”走向“能执行任务”,但可靠性、合规性和基础设施瓶颈也同步浮现。Cloudflare、Jio 和 Datasette 展示了 AI 如何更深地嵌入部署、通信和数据工作流;与此同时,LLM 架构突破、安全对齐、知识工作能力和搜索责任等议题,正在重新定义这类系统的边界。
Overview
从 24 条资讯中筛选出 12 条
今天的核心主题是:AI 正从“能回答问题”走向“能执行任务”,但可靠性、合规性和基础设施瓶颈也同步浮现。Cloudflare、Jio 和 Datasette 展示了 AI 如何更深地嵌入部署、通信和数据工作流;与此同时,LLM 架构突破、安全对齐、知识工作能力和搜索责任等议题,正在重新定义这类系统的边界。
临时账户和 `wrangler deploy --temporary` 让代理可立即上线并在 60 分钟内被认领,直接减少注册、令牌和 MFA 对自动化工作流的阻塞。
Subquadratic 宣称突破 transformer 瓶颈,而 AA-Briefcase 则显示顶级模型在长周期、多来源任务上依旧难以稳定交付,二者共同勾勒出“能力提升不等于可靠工作”的现实。
OpenAI 的有益特质训练研究、Anthropic 模型被叫停、以及谷歌 AI 概览的责任诉讼,都表明 AI 系统的可控性与法律归属正在重塑产品发布方式。
Jio 把 AI 嵌入通信网络和家庭设备,Elastic 通过收购补强 AI SRE,DeepMind 人才继续外流,说明竞争焦点正在从模型本身延伸到入口、运维与组织能力。
路透社数据显示,聊天机器人新闻使用率上升到 10%,但原始来源点击仍很少,意味着 AI 正在改变信息发现方式,却尚未赢得足够的新闻可信度。
AI 正在从模型能力竞赛,转向“如何真正上线、真正使用、真正治理”的系统竞争。今天的故事集中反映了三条主线:一是 AI 代理和工作流基础设施正在加速落地;二是行业仍在寻找更便宜、更长上下文、更安全的模型路径;三是监管、出口管制与平台责任正成为 AI 扩张的硬约束。
Cloudflare 的临时账户让代理无需完成传统注册即可部署网站、API 和 Workers,这是对自治编码代理的一次直接适配。[2643] 与此同时,Datasette Apps 把沙盒 HTML/JS 应用引入数据发布平台,强化了“数据 + 交互式小应用”的新形态。[2649] 这两则消息共同指向一个趋势:AI 不再只是生成内容,而是在更安全的权限边界内参与部署、分析和交付。
Subquadratic 声称突破 LLM 架构瓶颈,强调更长文本处理能力和更低推理成本。[2644] 但 AA-Briefcase 基准显示,顶级模型在真实、多周、跨来源的知识工作中仍然表现吃力,最好模型也只能完全满足 3% 的任务。[2647] 这形成鲜明对照:模型宣传的“更强”与现实工作所需的“更稳”之间仍有巨大鸿沟。
OpenAI 研究显示,少量关于诚实、谦逊、可纠正性等“有益特质”的强化学习,能显著提升模型跨领域安全性和抗操控能力。[2648] 但监管环境也在收紧:美国质疑 ASML EUV 设备是否流入中国,凸显先进芯片供应链的地缘政治风险;[2641] 美国叫停 Anthropic 的 Fable 5 和 Mythos 5,说明模型发布已可能直接触发国家安全层面的干预。[2650] 另一方面,谷歌就 AI 概览责任裁定提起上诉,也表明 AI 搜索输出的法律归属仍未定型。[2652]
DeepMind 的 John Jumper 转投 Anthropic,延续了前沿 AI 人才向竞争对手流动的趋势。[2642] Elastic 拟收购 Deductive AI,则显示企业软件公司正在通过并购补齐 AI SRE 能力。[2653] 在分发端,Reliance Jio 把 AI 嵌入电话、应用和家庭设备,试图把助手直接放进 5 亿用户的日常触点里。[2651] 这意味着未来竞争不只在模型参数,更在谁掌握用户入口、工作流和部署渠道。
路透社研究显示,AI 聊天机器人作为新闻入口的使用率升至 10%,但只有 1% 的人把它们当作主要新闻来源,信任和原始来源点击率仍然偏低。[2654] 这说明 AI 在信息分发上已经变得重要,但离“可信的默认入口”还有距离。
今天的新闻共同说明:AI 产业正在从“演示期”进入“系统期”。真正决定下一阶段胜负的,不只是模型是否更聪明,而是它能否在部署、验证、合规、可靠性和分发上同时过关。[2643][2647][2652][2654]
Stories
Cloudflare AI

Cloudflare 推出了面向代理的临时账户,让 AI 代理无需先完成传统注册流程,就能立即部署网站、API 和 Workers。使用最新的 Wrangler CLI,代理可以运行 `wrangler deploy --temporary` 创建一个临时部署,该部署会保持 60 分钟有效,之后还可以被认领为正式账户。
这消除了自治编码代理的一个关键阻碍,因为它们常常会被浏览器注册、API 令牌处理和多因素认证提示卡住。它让“编写—部署—验证”的循环更快、更稳定,这对代理开发工具和争夺默认部署目标的云平台都很重要。
Cloudflare 表示,AI 代理正在越来越多地编写代码,但当部署环节需要人类式的注册和认证步骤时,它们就会被卡住。为了解决这个问题,Cloudflare 正在推出面向代理的临时账户。这个新流程允许代理立即部署网站、API 和 Workers,而不必先创建普通账户。代理可以运行 `wrangler deploy --temporary` 来创建一个临时的 Worker 部署。该部署会保持 60 分钟有效,在此期间,用户可以认领这个临时账户,并将其变成永久账户。
如果没人认领,账户会自动过期。Cloudflare 说,这一设计目标是让代理更少受阻地完成“编码并上线”。公司还更新了 Wrangler:当代理在未授权状态下首次尝试部署时,CLI 会提示它使用新的参数。文章中的示例流程显示,代理先写出一个简单的 TypeScript Worker,然后完成部署,再用 curl 检查预览链接验证结果,之后还可以在同一个临时账户内继续修改代码并重新部署。
Cloudflare 还更新了 Wrangler:如果代理在未登录的情况下先尝试部署,系统会明确提示它使用 `--temporary` 参数。临时账户创建后,Cloudflare 会给 Wrangler 提供 API 令牌和认领链接,并且在 60 分钟窗口内可以复用同一个临时账户多次重新部署。
MIT Technology Review AI

迈阿密初创公司 Subquadratic 表示,它的新模型 SubQ 突破了长期制约大语言模型的瓶颈,且最近获得了第三方 Appen 的独立评估支持。该公司称,SubQ 更快、更便宜、能耗更低,还能一次处理多达 12 倍的文本,同时在编程等任务上接近顶级模型表现。
如果这些说法成立,SubQ 可能显著降低 LLM 推理的成本和能耗,并支持更长的上下文窗口,用于文档分析、代码理解等高负载任务。这对受限于 transformer 二次注意力瓶颈的 AI 基础设施厂商和企业用户都很重要。
迈阿密的 AI 初创公司 Subquadratic 上个月低调亮相时,提出了一个大胆主张:它已经解决了困扰大语言模型将近十年的数学瓶颈。公司表示,其新模型 SubQ 比现有系统更快、更便宜,而且能耗低得多。Subquadratic 还声称,SubQ 一次可以处理的文本量最多达到大多数其他模型的 12 倍,这意味着它适合审阅数百份文档或大型代码库等任务。更引人注目的是,该公司称 SubQ 在编程等关键任务上的表现,基本可以与 Google DeepMind、OpenAI 和 Anthropic 的顶级模型相媲美。起初,Subquadratic 只公布了少量自发布的测试分数,而且并未让外界广泛使用 SubQ,因此很多人持怀疑态度。
有人甚至在 X 上调侃说,SubQ 不是“自 Transformer 以来最大的突破”,就是“AI Theranos”。一个月后,Subquadratic 发布了更多信息,其中包括第三方评测公司 Appen 对该模型进行的独立测试结果。Appen 的生成式 AI 研究负责人表示,这些结果验证了该架构,并让她觉得这可能会成为“改变游戏规则”的技术。Subquadratic 的联合创始人兼 CTO Alex Whedon 也承认,如果一开始就同步发布第三方基准,会减轻很多质疑,因此未来会在结果经过充分验证后再对外公布。公司联合创始人兼 CEO Justin Dangel 则表示,他们希望开启一个新的效率时代,并认为几年后不会再有人继续基于 transformer 构建模型。
Subquadratic 表示 SubQ 采用完全的亚二次架构,这意味着计算量增长速度低于 transformer 常见的 O(n²) 注意力机制。该模型目前尚未向公众广泛开放,因此这些说法仍主要依赖有限的公开证据和基准测试,而不是广泛的实际体验验证。
TechCrunch AI

彭博社报道称,美国商务部长霍华德·卢特尼克在近期多次会面中告诉ASML高管,他担心这家公司的某台EUV光刻机可能已经流入中国。ASML否认中国境内曾经存在任何EUV机器,而美国官员则声称他们掌握EUV相关组件和运输设备运往中国的证据。
ASML的EUV系统是目前全球唯一能够打印最先进半导体图案的工具,因此任何违规流入都可能对出口管制和先进AI供应链产生重大影响。此事不仅关系到ASML和中国,也关系到限制尖端芯片制造技术获取的更广泛努力。
据彭博社报道,美国商务部长霍华德·卢特尼克在最近与ASML高管的多次会面中表示担忧:这家荷兰公司的某台EUV光刻机可能已经流入中国。如果属实,这将构成重大出口管制违规,因为自第一届特朗普政府以来,ASML就被禁止向中国销售EUV系统。彭博社称,美国官员表示他们掌握ASML将EUV相关组件和运输设备运往中国的证据,但这些证据并未公开。美国商务部也没有回应彭博社关于是否存在一整套EUV系统实际位于中国的问题。ASML则坚决否认,称中国境内从未存在过任何EUV机器。
公司表示,它会追踪每一台已发货设备,并通过内部隔离机制,将接触EUV技术、文档和培训的员工与中国员工分开。ASML首席执行官克里斯托夫·富凯还表示,EUV设备之所以能够制造出来,是因为其中约80%建立在多年既有知识之上,而真正全新的难题——生成EUV光——本身就耗费了20年。ASML的意思是,若没有真正拿到机器,就无法对其进行逆向工程。文章还指出,从商业角度看,ASML不太可能冒着失去EUV禁售风险去秘密武装中国客户,因为它仍在向中国销售更旧一代的深紫外设备,预计2026年约20%的收入将来自这些获准销售。尽管如此,这篇报道并未最终证实指控,因为美国政府尚未公开其证据。
ASML表示,公司会追踪每一台已发货设备,且能够接触EUV技术的员工与其他员工之间设有内部隔离。该公司还向中国销售较旧的深紫外设备,并称预计约20%的2026年收入将来自已获许可的中国销售。
The Decoder
谷歌 DeepMind 的 AlphaFold 负责人、诺贝尔奖得主约翰·贾姆珀据报道在任职近九年后离开公司,转投 Anthropic。此次变动发生在谷歌多位知名 AI 研究员接连离职的背景下。
贾姆珀是 DeepMind 最具代表性的科研领军人物之一,他的离开进一步加剧了外界对前沿 AI 人才持续流向 Anthropic 和 OpenAI 等竞争对手的担忧。这可能影响谁能在 AI 行业中主导基础研究突破与产品路线。
谷歌 DeepMind 再次遭遇高层级研究人员流失,诺贝尔奖得主约翰·贾姆珀在任职近九年后离开公司,转投 Anthropic。贾姆珀曾担任 AlphaFold 团队负责人,并与 DeepMind 首席执行官 Demis Hassabis 共同获得 2024 年诺贝尔化学奖。文章称,AlphaFold 是一套改变蛋白质结构预测领域的 AI 系统,Hassabis 也公开感谢了贾姆珀的“非凡合作”。这次离职发生的时间点尤其敏感,因为此前 Gemini 联合负责人 Noam Shazeer 刚刚离开谷歌加入 OpenAI。
报道指出,Shazeer 是谷歌最新模型中推理方法背后的关键人物之一。短时间内,Anthropic 和 OpenAI 分别挖走了谷歌最重要的研究者之一。文章还提到,DeepMind 之前已经失去了 David Silver,他是 AlphaGo 和 AlphaZero 的核心研究者之一,后来离开去创办一家专注于世界模型和强化学习的初创公司。在这样的背景下,Gemini 3.5 Pro 据称将在 6 月下旬发布,但内部传闻显示它可能难以与 Anthropic 和 OpenAI 的最新模型竞争。
贾姆珀与 DeepMind 首席执行官 Demis Hassabis 共同获得了 2024 年诺贝尔化学奖,获奖工作是 AlphaFold,这一 AI 系统改变了蛋白质结构预测。文章还提到,Gemini 联合负责人 Noam Shazeer 近期转投 OpenAI,而此前 DeepMind 也失去了 AlphaGo 和 AlphaZero 重要研究者 David Silver。
The Decoder

Artificial Analysis推出了AA-Briefcase,这是一项面向长周期、代理式知识工作的基准测试,任务材料来自Slack线程、电子邮件、会议记录和大型数据导出等碎片化真实来源。报告显示,表现最好的模型Claude Fable 5也只能在3%的任务上完全满足所有评分标准。
这项基准说明,当前AI系统在需要跨多来源整合信息、并在长任务链中保持准确性的真实多周工作里仍然表现很差。这对希望用AI代理做真实办公自动化的团队很重要,因为它暴露了演示型聊天能力与可靠知识工作之间的巨大差距。
Artificial Analysis发布了AA-Briefcase,这是一项旨在评估AI真实知识工作能力的新基准,而不是只测试狭窄问答能力。该基准围绕长周期、多周项目构建,材料来自数千个碎片化来源文件,包括Slack线程、电子邮件、会议记录和大型数据导出。它的目标是衡量模型处理现实职场中那种杂乱信息整合任务的能力。最引人注目的结果是,即便是表现最好的Claude Fable 5,也只能在3%的任务上完全满足全部评分标准。在91个任务中,有31个任务没有任何模型能达到50%以上的分数。
报告还发现,不同能力水平的模型会以不同方式失败。较弱模型通常卡在基础执行上,比如漏掉相关文件或输出不可用结果。更强的模型虽然能满足表面要求,但仍会错过需要跨多个来源拼接证据才能发现的细节。价格差异同样惊人,单任务成本从DeepSeek V4 Flash的大约0.04美元,到Claude Fable 5的31美元以上不等。总体来看,这些结果表明,当前前沿模型距离大规模、可靠地胜任真实知识工作仍然很远。
Artificial Analysis表示,这项基准使用由数千个碎片化文件拼成的复杂项目,而AA-Briefcase Elo指标则综合了评分规程通过率、分析质量和呈现质量。报告还指出,模型越强,错误类型越不同:较弱模型常常漏掉关键文件或输出不可用结果,而较强模型则更容易满足显性要求,却忽略跨来源整合后才能发现的细节。
The Decoder

OpenAI研究人员报告称,只需在强化学习中加入少量关于诚实、认识论上的谦逊、可纠正性、推理透明度、公平性以及对人类福祉关注等有益特质的训练,模型就会变得更安全。 这些提升还能跨越医疗、教育、科学、法律和工程等不同领域。
这一结果说明,围绕少量精心选择的行为进行对齐训练,可能比原始示例覆盖更广的场景,这对真实部署中的模型安全非常重要。 它也为降低欺骗、奖励黑客和有害操控提供了一条可行路径,同时不必牺牲模型的实用灵活性。
OpenAI研究人员测试了一个问题:如果“坏行为”会跨领域扩散,那么“好行为”是否也能同样跨领域泛化。 根据OpenAI对齐博客的介绍,研究团队使用强化学习训练模型,让它在真实对话场景中表现出诚实、认识论上的谦逊、可纠正性、推理透明度、公平性以及对人类福祉的关注等特质。 这些场景覆盖了医疗、教育、科学、法律和工程等多个领域。 研究中只有一小部分“有益特质”数据被混入常规的RL后训练流程。
尽管如此,模型仍在53项独立基准中的44项上取得了提升,这些基准涉及欺骗、诚实、谄媚、奖励黑客以及健康和心理健康任务。 研究人员还发现,仅用健康数据训练也能改善非健康评估,而在不使用健康或科学数据的情况下,模型依然能提升健康基准表现,这说明学到的行为模式可以跨领域迁移。 在对抗性测试中,原本会严重扰乱基线模型的提示,对经过有益特质训练的模型影响小得多,有害微调也更难抹去这些已学到的特质。 与此同时,模型对有帮助的指令仍然保持同样的可控性,研究团队将这种现象称为“选择性持久性”。
研究人员表示,这些有益特质数据只占常规RL后训练流程中的很小一部分,但模型仍在53项独立基准中的44项上得到提升。 他们还发现,经过训练的模型对对抗性提示和有害微调更具抵抗力,但对有帮助的指令仍然同样可控,研究团队将这一现象称为“选择性持久性”。
Simon Willison
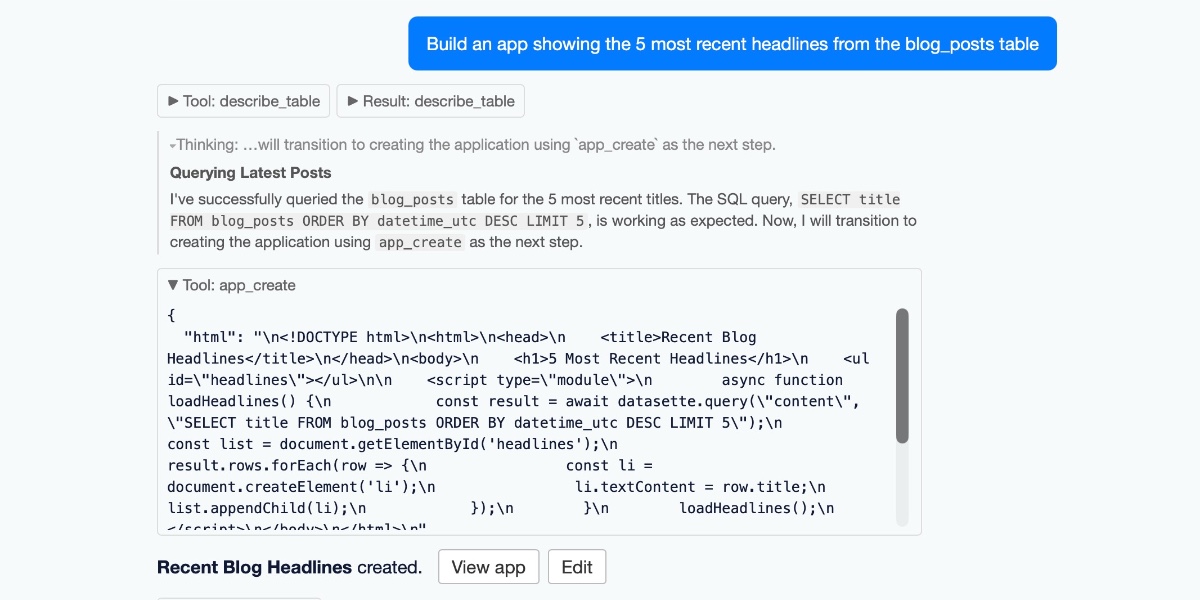
Datasette 发布了一个名为 datasette-apps 的新插件。它允许开发者在受沙盒保护的 iframe 中托管独立的 HTML 和 JavaScript 应用,并可使用只读 SQL 访问数据,若配置了存储查询,也可以获得写入能力。
这让 Datasette 从一个数据发布工具,进一步变成了一个可以构建交互式、数据感知型小应用的平台。对于希望快速交付自定义分析、搜索或工作流界面,同时又不暴露数据或赋予应用过大浏览器权限的开发者来说,这会很有用。
Simon Willison 发布了 datasette-apps,这是一个新的 Datasette 插件,用于直接在 Datasette 内托管自定义的 HTML+JavaScript 应用。 这些应用是自包含的,并且运行在 Datasette 网站中的一个严格受限的 iframe 沙盒里。 在这个沙盒内,它们可以渲染 HTML、CSS 和 JavaScript,并且可以针对底层 Datasette 数据库执行只读 SQL 查询。 如果实例配置了存储查询,这些应用还可以执行写入查询。 Willison 表示,这套方案同时使用了 iframe 限制和注入的内容安全策略(CSP),以防止应用访问 cookies、localStorage 或向外部网络发起请求。
这样做的目标是降低有缺陷或恶意应用外泄私有数据的风险。 他还解释说,这个功能最初是为 Datasette Agent 尝试构建一种类似 Claude Artifacts 的机制,但他很快意识到,这种沙盒模式的用途远不止聊天界面中的自定义应用。 这次发布也延续了他长期以来对 HTML 工具的实验,并把这些实验提升为 Datasette 生态中的核心能力。 用户可以通过 GitHub 登录 agent.datasette.io 的演示实例来试用这一功能。
这些应用运行在 iframe 沙盒中,并配有严格的 CSP,无法访问 cookies、localStorage,也不能向外部主机发起 HTTP 请求。该插件本身并不依赖 LLM,不过 Simon Willison 提到,这种应用形态很适合由现代 LLM 生成。
TechCrunch AI

美国政府以国家安全担忧为由,迫使 Anthropic 下架其两款最新模型 Fable 5 和 Mythos 5,据称原因是亚马逊研究人员找到了一种绕过 Fable 5 保护栏的方法。TechCrunch 的 Equity 播客节目讨论了这一举动及其对 Anthropic、开发者和监管者的影响。
这件事很重要,因为它表明模型发布可能迅速演变为监管和安全问题,尤其是对于开发者高度依赖其平台的大型 AI 厂商而言。它可能影响公司发布新模型的节奏、政府介入的方式,以及投资者对 Anthropic 走向 IPO 的看法。
在上周末临近结束时,美国政府据称以国家安全为由,迫使 Anthropic 撤回其两款最新模型 Fable 5 和 Mythos 5。导火索是有报道称,亚马逊研究人员找到了绕过 Fable 5 保护栏的方法。随后,网络安全研究人员联名签署公开信,警告这一举动本身可能带来危险。Anthropic 也表示,类似的越狱方法并不是其模型独有,其他系统中同样存在。
TechCrunch 的 Equity 播客主持人 Anthony Ha、Sean O’Kane 和 Rebecca Bellan 围绕这一事件展开讨论,分析它究竟是真实的安全风险,还是 Anthropic 与特朗普政府之间更广泛政治摩擦的又一章节。节目还探讨了这次撤回对依赖 Anthropic 平台开发的开发者意味着什么。主持人们也提出,这场争议或许会在意外中提升 Anthropic 的关注度,从而对其未来 IPO 产生影响。
网络安全研究人员联名签署公开信,认为这项禁令很危险,而 Anthropic 也表示,其他模型中同样存在这些越狱方法。节目将这一事件描述为 Anthropic 与特朗普政府之间更广泛、较为复杂关系的一部分,而不只是一次孤立的技术失误。
TechCrunch AI

信实集团宣布推出 Jio Call Agent,这是一款可以加入电话通话、进行转写、总结内容并协助完成叫车、订餐和预订等任务的 AI 助手。公司还发布了支持 AI 的 MyJio 应用和名为 TeleFrame 的家庭显示设备,目标用户是 Jio 超过 5 亿的用户。
这是一项将 AI 直接嵌入电信服务而非作为独立应用提供的重大尝试,可能让信实集团在印度获得分发优势。若成功,它可能重塑数亿消费者在日常通话、手机操作和智能家居设备中使用 AI 的方式。
信实集团在年度股东大会上展示了一项围绕印度消费者服务展开的全面 AI 计划。穆克什·安巴尼表示,公司希望印度不仅仅是使用外部开发的 AI,而是成为 AI 的创造者和全球领导者。最受关注的产品是 Jio Call Agent,这是一款可以加入电话通话、转写对话、生成摘要,并执行叫车、订餐和预订等操作的 AI 助手。该助手可通过说“Hey Jio”唤醒,计划在今年晚些时候面向 Jio 超过 5 亿用户推出。信实集团表示,其思路是把助手直接嵌入电信网络,而不是要求用户单独安装应用。
公司还推出了支持 AI 的 MyJio 应用,可通过自然语言请求处理激活 eSIM、选择漫游套餐等任务。面向家庭场景的 TeleFrame 则会利用 AI 代理主动展示天气提醒、日程安排和家庭通知。除了消费级产品之外,公司还发布了面向医疗、教育、农业和小企业的 AI 服务,名称包括 JioHealthIQ、JioLearnIQ、JioKrishiIQ 和 AI Vyapar。信实集团表示,这些服务将支持多种印度语言并适配本地需求,同时 Jio Platforms 董事会也已批准一份 IPO 招股书草案,其中包括最多 2.7 亿股的新发行计划。
Jio Call Agent 预计将于今年晚些时候上线,可通过说“Hey Jio”唤起,并通过 Jio 网络在用户同意下运行。信实集团还表示,其更广泛的 AI 战略将覆盖医疗、教育、农业和小企业,但用户数据如何处理、是否用于训练模型或与合作伙伴共享仍未说明。
The Decoder

谷歌表示将上诉慕尼黑地区法院的一项裁定,该裁定认定公司对其AI生成的搜索概览中的错误内容承担直接责任。该案涉及AI概览错误地将两家总部位于慕尼黑的出版商与欺诈计划联系起来。
这项裁定提高了AI搜索产品的法律风险,因为它把AI概览视为谷歌自己的内容,而不是普通搜索结果。若该裁定成立,可能会影响欧洲乃至更广范围内大型搜索平台展示AI生成答案时的责任标准。
谷歌已经宣布,将对德国慕尼黑地区法院在2026年5月下旬作出的裁定提起上诉。该法院认定,谷歌AI生成的搜索概览内容应被视为独立内容,因此谷歌要对其中的错误承担直接责任。涉案内容错误地将两家位于慕尼黑的出版商与欺诈计划联系在一起。谷歌表示不同意这一判决,并称此案只涉及“具体且有限的错误”,而不是AI Overviews展示网页内容的根本方式出了问题。
不过,谷歌并没有明确说明,什么样的错误会被视为例外,什么又会影响整个产品。此次上诉之所以重要,是因为AI Overviews已经成为谷歌搜索的重要功能,并且使用规模很大。报道称,柏林法院在6月初的另一宗不同案件中得出了相反结论,认为AI Overviews只是搜索结果的另一种形式,谷歌的责任应当像传统搜索引擎那样受到限制。谷歌很可能会在上诉中援引这一柏林裁定,继续推动围绕AI搜索答案责任边界的法律争议。
谷歌称此案只涉及“具体且有限的错误”,并不代表AI Overviews的整体设计,但并未清楚说明这一界限到底在哪里。另有消息称,柏林法院在另一宗不同案件中得出了相反结论,认为AI概览只是搜索结果的另一种形式,谷歌仅承担有限责任。
TechCrunch AI

据知情人士透露,Elastic已同意以最高8500万美元收购Deductive AI。Deductive AI成立于2023年,专注于用AI发现并解决软件漏洞,并在去年11月结束隐身后宣布获得750万美元种子轮融资。
这笔交易表明,AI SRE工具正迅速成为企业软件厂商争夺的战略方向。若整合顺利,Deductive的技术有望增强Elastic的可观测性产品,帮助自动化故障发现、分诊和修复。
据报道,Elastic即将以最高8500万美元收购专注于发现并修复软件漏洞的AI初创公司Deductive AI。该消息来自一位知情人士,而Elastic和Deductive都尚未公开回应。Deductive成立于2023年,并在去年11月结束隐身,随后宣布获得由CRV领投的750万美元种子轮融资,Databricks Ventures、Thomvest Ventures和PrimeSet也参与了投资。根据PitchBook的数据,那轮融资时公司的估值为3300万美元。这笔交易如果完成,将成为这家年轻公司在AI site reliability engineering,也就是AI SRE领域的一次快速退出。AI SRE工具利用AI辅助故障发现、根因分析和其他可靠性工作,尤其是在AI生成代码大幅增加的背景下。
消息人士称,这也符合一个更广泛的趋势,即成熟厂商收购AI原生初创公司,把智能代理技术整合进现有产品线。Elastic于2018年上市,以Elasticsearch以及搜索、可观测性和安全产品而闻名。该公司的可观测性软件有望受益于Deductive的技术,帮助客户实时监控性能并应对系统故障。Deductive由Rakesh Kothari和Sameer Agarwal共同创立,前者曾任ThoughtSpot工程副总裁,后者曾在Apache Software Foundation、Meta任职,也是Databricks的创始工程师之一。消息人士还表示,Deductive的年度经常性收入约为100万美元,但增长速度落后于更受关注的竞争对手Resolve AI,后者在4月完成4000万美元A轮延长融资时估值达到15亿美元。
据称,Deductive的年度经常性收入约为100万美元,但增长速度落后于同领域更受关注的竞争对手Resolve AI。该公司由Rakesh Kothari和Sameer Agarwal共同创立,这笔收购也反映出传统科技公司正在通过并购AI原生初创企业来补充智能代理能力的趋势。
The Decoder

路透社研究所的《2026年数字新闻报告》显示,全球每周通过 AI 聊天机器人获取新闻的比例已从 7% 上升到 10%。尽管如此,只有 1% 的受访者把聊天机器人视为主要新闻来源,而且人们对 AI 生成新闻的信任仍然有限。
这些结果表明,AI 聊天机器人正在成为新闻消费中的一个真实但仍然有限的部分,尤其是在更年轻、更关注新闻的人群中。它们也凸显了信息完整性方面的风险:用户往往接受聊天机器人的回答,却很少回头核对原始来源。
路透社研究所的《2026年数字新闻报告》显示,AI 聊天机器人如 ChatGPT 和 Google Gemini 在新闻消费中的作用正在变大,但总体规模仍然不高。全球每周通过聊天机器人获取新闻的比例已从 7% 上升到 10%,不过只有 1% 的受访者表示聊天机器人是他们的主要新闻来源。增长主要来自亚洲、非洲、拉丁美洲以及南欧和东欧的市场。使用情况也明显偏向年轻人以及本来就更关注新闻的人群。18 至 24 岁受访者中有 17% 会用聊天机器人看新闻,而最年长组只有 5%。报告还发现,自称“新闻爱好者”的人以及政治立场更极端的人,使用聊天机器人的比例更高。
聊天机器人的主要用途包括追问细节、获取最新新闻、生成摘要、检查新闻来源可靠性,以及把新闻内容解释得更简单。在新闻自由度较低或公众对新闻信任较低的市场里,用聊天机器人核实来源的比例尤其高。信任仍然是最大障碍:在普通人群中,只有 20% 的人信任 AI 聊天机器人提供的新闻,但在真实使用者中,这一比例升至 44%。来源点击同样很少,只有 4% 的受访者表示他们会经常或总是点击聊天机器人给出的原始来源。报告认为,这可能与人们是主动使用聊天机器人有关,但也说明很多用户会直接接受答案,而不会去核实信息从何而来。
在实际使用者中,44% 的人信任 AI 生成新闻,但放到整体人群里,这一比例只有 20%。在 27 个市场中,只有 4% 的受访者表示会经常或总是从聊天机器人点击到原始来源,而搜索引擎和社交媒体分别为 19% 和 17%。